Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
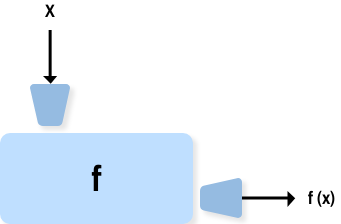
return statementdef NAME( LIST OF PARAMETERS ):
STATEMENTSdef f(x):
return 3 * x ** 2 - 2 * x + 5>>> f(3)
26
>>> f(0)
5
>>> f(1)
6
>>> f(-1)
10
>>> f(5)
70>>> def f(x):
... return 3 * x ** 2 - 2 * x + 5
...
>>>>>> result = f(3)
>>> result
26
>>> result = f(3) + f(-1)
>>> result
36>>> def mystery():
... return
...
>>> what_is_it = mystery()
>>> what_is_it
>>> type(what_is_it)
<class 'NoneType'>
>>> print(what_is_it)
None>>> def do_nothing_useful(n, m):
... x = n + m
... y = n - m
...
>>> do_nothing_useful(5, 3)
>>> result = do_nothing_useful(5, 3)
>>> result
>>>
>>> print(result)
None>>> def try_to_print_dead_code():
... print("This will print...")
... print("...and so will this.")
... return
... print("But not this...")
... print("because it's dead code!")
...
>>> try_to_print_dead_code()
This will print...
...and so will this.
>>>def f1():
print("Moe")
def f2():
f4()
print("Meeny")
def f3():
f2()
print("Miny")
f1()
def f4():
print("Eeny")
f3()Eeny
Meeny
Miny
Moenumber = 4203
count = 0
while number != 0:
count += 1
number //= 10
print(count)def num_digits():
number = 4203
count = 0
while number != 0:
count += 1
number //= 10
return count
print(num_digits())def num_digits(number):
count = 0
while number != 0:
count += 1
number //= 10
return count
print(num_digits(4203))>>> def f(x):
... return 2 * x
...
>>> def g(x):
... return x + 5
...
>>> def h(x):
... return x ** 2 - 3
>>> f(3)
6
>>> g(3)
8
>>> h(4)
13
>>> f(g(3))
16
>>> g(f(3))
11
>>> h(f(g(0)))
97
>>>>>> # Assume function definitions for f and g as in previous example
>>> val = 10
>>> f(val)
20
>>> f(g(val))
30
>>>>>> def f():
... print("Hello from function f!")
...
>>> type(f)
<type 'function'>
>>> f()
Hello, from function f!
>>>>>> do_stuff = [f, g, h]
>>> for func in do_stuff:
... func(10)
...
20
15
97def double_stuff_v1(a_list):
index = 0
for value in a_list:
a_list[index] = 2 * value
index += 1>>> from pure_v_modify import double_stuff_v1
>>> things = [2, 5, 'Spam', 9.5]
>>> double_stuff_v1(things)
>>> things
[4, 10, 'SpamSpam', 19.0]def double_stuff_v2(a_list):
new_list = []
for value in a_list:
new_list += [2 * value]
return new_list>>> from pure_v_modify import double_stuff_v2
>>> things = [2, 5, 'Spam', 9.5]
>>> double_stuff_v2(things)
[4, 10, 'SpamSpam', 19.0]
>>> things
[2, 5, 'Spam', 9.5]
>>>>>> things = double_stuff(things)
>>> things
[4, 10, 'SpamSpam', 19.0]
>>>>>> def double(thing):
... return 2 * thing
...
>>> double(5)
10
>>> double('Spam')
'SpamSpam'
>>> double([1, 2])
[1, 2, 1, 2]
>>> double(3.5)
7.0
>>> double(('a', 'b'))
('a', 'b', 'a', 'b')
>>> double(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in double
TypeError: unsupported operand type(s) for *: 'int' and 'NoneType'
>>>for i in range(1, 7):
print(2 * i, end=" ")
print()2 4 6 8 10 12def print_multiples(n):
for i in range(1, 7):
print(n * i, end=" ")
print()3 6 9 12 15 184 8 12 16 20 24for i in range(1, 7):
print_multiples(i)1 2 3 4 5 6
2 4 6 8 10 12
3 6 9 12 15 18
4 8 12 16 20 24
5 10 15 20 25 30
6 12 18 24 30 36def print_mult_table():
for i in range(1, 7):
print_multiples(i)>>> sum([1, 2, 8])
11
>>> sum((3, 5, 8.5))
16.5
>>>>>> sum([1, 2, [11, 13], 8])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'list'
>>>def recursive_sum(nested_num_list):
the_sum = 0
for element in nested_num_list:
if type(element) == list:
the_sum = the_sum + recursive_sum(element)
else:
the_sum = the_sum + element
return the_sumdef recursive_max(nested_num_list):
"""
>>> recursive_max([2, 9, [1, 13], 8, 6])
13
>>> recursive_max([2, [[100, 7], 90], [1, 13], 8, 6])
100
>>> recursive_max([2, [[13, 7], 90], [1, 100], 8, 6])
100
>>> recursive_max([[[13, 7], 90], 2, [1, 100], 8, 6])
100
"""
largest = nested_num_list[0]
while type(largest) == type([]):
largest = largest[0]
for element in nested_num_list:
if type(element) == type([]):
max_of_elem = recursive_max(element)
if largest < max_of_elem:
largest = max_of_elem
else: # element is not a list
if largest < element:
largest = element
return largest#
# infinite_recursion.py
#
def recursion_depth(number):
print "Recursion depth number %d." % number
recursion_depth(number + 1)
recursion_depth(0)python infinite_recursion.py ...
File "infinite_recursion.py", line 3, in recursion_depth
recursion_depth(number + 1)
RuntimeError: maximum recursion depth exceeded>>> print 55/0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: integer division or modulo by zero
>>>>>> a = []
>>> print a[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>>>>> tup = ('a', 'b', 'd', 'd')
>>> tup[2] = 'c'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>>filename = raw_input('Enter a file name: ')
try:
f = open (filename, "r")
except:
print 'There is no file named', filenamedef exists(filename):
try:
f = open(filename)
f.close()
return True
except:
return False#
# learn_exceptions.py
#
def get_age():
age = input('Please enter your age: ')
if age < 0:
raise ValueError, '%s is not a valid age' % age
return age>>> get_age()
Please enter your age: 42
42
>>> get_age()
Please enter your age: -2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "learn_exceptions.py", line 4, in get_age
raise ValueError, '%s is not a valid age' % age
ValueError: -2 is not a valid age
>>>#
# infinite_recursion.py
#
def recursion_depth(number):
print "Recursion depth number %d." % number
try:
recursion_depth(number + 1)
except:
print "Maximum recursion depth exceeded."
recursion_depth(0)def countdown(n):
if n == 0:
print "Blastoff!"
else:
print n
countdown(n-1)def find_max(seq, max_so_far):
if not seq:
return max_so_far
if max_so_far < seq[0]:
return find_max(seq[1:], seq[0])
else:
return find_max(seq[1:], max_so_far)0! = 1
n! = n(n-1)def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)fibonacci(0) = 1
fibonacci(1) = 1
fibonacci(n) = fibonacci(n-1) + fibonacci(n-2)def fibonacci (n):
if n == 0 or n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)for loopenumeratein operatordir() function and docstringscount and index methodscolors = ['red', 'blue', 'green']type = ['hello', 3.14, 420]# List Initialization and Assignment
colors = ['red', 'blue', 'green']
# Output: 'red'
print(colors[0])
# Nested List
nest = [[0, 1, 2], [3, 4, 5]]
# Output: 4
print(nest[1][1])
# Error Thrown: IndexError
print(colors[3])
# Error Thrown: TypeError
print(colors[1.0])colors = ['red', 'blue', 'green']
# Output: 'green'
print(colors[-1])nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# This notation slices from start index -> stop index - 1
# Output: [0, 1, 2, 3]
print(nums[0:4])
# The third number in the notation defines the step (indices to skip)
# By default, step is 1.
# Output: [0, 2]
print(nums[0:4:2])
# If step is a negative number, it slices from the end of list (reverse)
# Output: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
print(nums[::-1])
# Output: [0, 1, 2, 3, 4] (beginning to 4th)
print(nums[:-5])
# Output: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(nums[:])# vowels list
vowels = ['a', 'e', 'i', 'o', 'i', 'u']
# index of 'e' in vowels
index = vowels.index('e')
# Output: 1
print(index)
index = vowels.index('x')
# Output: Throws ValueError exceptionfruits = ['apple']
fruits.append('orange')
# Output: ['apple', 'orange']
print(fruits)animals = ['lion', 'tiger']
animals1 = ['wolf', 'panther']
animals.extend(animals1)
print(animals)
# Output: ['lion', 'tiger', 'wolf', 'panther']nums = [1, 2, 3, 4, 5]
nums.insert(5, 6)
# Note: the element 6 is inserted in the index 5
print(nums)
# Output: [1, 2, 3, 4, 5, 6]languages = ['english', 'tamil', 'french']
languages.remove('tamil')
print(languages)
# Output: ['english', 'french']
# Throws not in list exception
languages.remove('tamil')counts = [0, 1, 2, 3, 2, 1, 4, 6, 2]
print(list.count(2))
# Output: 3alpha = ['a', 'b', 'c', 'd', 'e']
x = alpha.pop()
# Output: 'e'
print(x)
# Output: ['a', 'b', 'c', 'd']
print(alpha)alpha = ['a', 'b', 'c', 'd', 'e']
alpha.reverse()
# Output: ['e', 'd', 'c', 'b', 'a']
print(alpha)# vowels list
vowels = ['e', 'a', 'u', 'o', 'i']
# sort the vowels
vowels.sort()
# print vowels
print(vowels)
# Output: ['a', 'e', 'i', 'o', 'u']
# sort in reverse
vowels.sort(reverse=True)
# print vowels
print(vowels)
# Output: ['u', 'o', 'i', 'e', 'a']list1 = [1, 2, 3]
list2 = list1.copy()
# Output: [1, 2, 3]
print(list2)l = ['hello', 'world']
# Output: ['hello', 'world']
print(l)
# Clearing the list
l.clear()
# Output: []
print(l)# The below statement creates a list with 5, 10, ...
p = [5 + x for x in range(5)]
# Output: [5, 10, 15, 20, 25]
print(p)[10, 20, 30, 40, 50]
["spam", "bungee", "swallow"]
(2, 4, 6, 8)
("two", "four", "six", "eight")
[("cheese", "queso"), ("red", "rojo"), ("school", "escuela")]>>> thing = 2, 4, 6, 8
>>> type(thing)
<class 'tuple'>
>>> thing
(2, 4, 6, 8)>>> singleton = (2,)
>>> type(singleton)
<class 'tuple'>
>>> not_tuple = (2)
>>> type(not_tuple)
<class 'int'>
>>> empty_tuple = ()
>>> type(empty_tuple)
<class 'tuple'>>>> fruit = "banana"
>>> fruit[1]
'a'
>>> fruits = ['apples', 'cherries', 'pears']
>>> fruits[0]
'apples'
>>> prices = (3.99, 6.00, 10.00, 5.25)
>>> prices[3]
5.25
>>> pairs = [('cheese', 'queso'), ('red', 'rojo'), ('school', 'escuela')]
>>> pairs[2]
('school', 'escuela')>>> len('banana')
6>>> len(['a', 'b', 'c', 'd'])
4
>>> len((2, 4, 6, 8, 10, 12))
6
>>> pairs = [('cheese', 'queso'), ('red', 'rojo'), ('school', 'escuela')]
>>> len(pairs)
3>>> seq = [1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0]
>>> last = seq[len(seq)] # ERROR!>>> last = seq[len(seq) - 1]>>> prime_nums = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31]
>>> prime_nums[-2]
29
>>> classmates = ("Alejandro", "Ed", "Kathryn", "Presila", "Sean", "Peter")
>>> classmates[-5]
'Ed'
>>> word = "Alphabet"
>>> word[-3]
'b'prime_nums = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31]
for num in prime_nums:
print(num ** 2)fruits = ['apples', 'bananas', 'blueberries', 'oranges', 'mangos']
for index, fruit in enumerate(fruits):
print("The fruit, " + fruit + ", is in position " + str(index) + ".")>>> singers = "Peter, Paul, and Mary"
>>> singers[0:5]
'Peter'
>>> singers[7:11]
'Paul'
>>> singers[17:21]
'Mary'
>>> classmates = ("Alejandro", "Ed", "Kathryn", "Presila", "Sean", "Peter")
>>> classmates[2:4]
('Kathryn', 'Presila')>>> fruit = "banana"
>>> fruit[:3]
'ban'
>>> fruit[3:]
'ana'>>> fruit[-2:]
'na'
>>> classmates[:-2]
('Alejandro', 'Ed', 'Kathryn', 'Presila')>>> strange_list = [(1, 2), [1, 2], '12', 12, 12.0]
>>> print(strange_list[0], type(strange_list[0]))
(1, 2) <class 'tuple'>
>>> print(strange_list[0:1], type(strange_list[0:1]))
[(1, 2)] <class 'list'>
>>> print(strange_list[2], type(strange_list[2]))
12 <class 'str'>
>>> print(strange_list[2:3], type(strange_list[2:3]))
[12] <class 'list'>
>>>>>> stuff = ['this', 'that', 'these', 'those']
>>> 'this' in stuff
True
>>> 'everything' in stuff
False
>>> 4 in (2, 4, 6, 8)
True
>>> 5 in (2, 4, 6, 8)
False>>> 'p' in 'apple'
True
>>> 'i' in 'apple'
False
>>> 'ap' in 'apple'
True
>>> 'pa' in 'apple'
False>>> 'a' in 'a'
True
>>> 'apple' in 'apple'
True
>>> '' in 'a'
True
>>> '' in 'apple'
True>>> 'apple'.upper()
'APPLE'
>>> 'COSATU'.lower()
'cosatu'
>>> 'rojina'.capitalize()
'Rojina'
>>> '42'.isdigit()
True
>>> 'four'.isdigit()
False
>>> ' remove_the_spaces '.strip()
'remove_the_spaces'
>>> 'Mississippi'.startswith('Miss')
True
>>> 'Aardvark'.startswith('Ant')
False >>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__doc__',
'__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__',
'__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__',
'__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'capitalize', 'center', 'count', 'encode', 'endswith', 'expandtabs',
'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha',
'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric',
'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust',
'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind',
'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split',
'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate',
'upper', 'zfill']
>>>>>> print(str.replace.__doc__)
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.>>> 'Mississippi'.replace('i', 'X')
'MXssXssXppX'
>>> 'Mississippi'.replace('p', 'MO')
'MississiMOMOi'
>>> 'Mississippi'.replace('i', '', 2)
'Mssssippi'>>> print(str.count.__doc__)
S.count(sub[, start[, end]]) -> int
Return the number of non-overlapping occurrences of substring sub in
string S[start:end]. Optional arguments start and end are
interpreted as in slice notation.
>>> print(tuple.count.__doc__)
T.count(value) -> integer -- return number of occurrences of value
>>> print(list.count.__doc__)
L.count(value) -> integer -- return number of occurrences of value
>>> print(str.index.__doc__)
S.index(sub[, start[, end]]) -> int
Like S.find() but raise ValueError when the substring is not found.
>>> print(tuple.index.__doc__)
T.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
>>> print(list.index.__doc__)
L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.>>> fruit = ["banana", "apple", "quince"]
>>> fruit[0] = "pear"
>>> fruit[-1] = "orange"
>>> fruit
['pear', 'apple', 'orange']>>> my_string = 'TEST'
>>> my_string[2] = 'X'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment>>> my_list = ['T', 'E', 'S', 'T']
>>> my_list[2] = 'X'
>>> my_list
['T', 'E', 'X', 'T']>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> a_list[1:3] = ['x', 'y']
>>> a_list
['a', 'x', 'y', 'd', 'e', 'f']>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> a_list[1:3] = []
>>> a_list
['a', 'd', 'e', 'f']>>> a_list = ['a', 'd', 'f']
>>> a_list[1:1] = ['b', 'c']
>>> a_list
['a', 'b', 'c', 'd', 'f']
>>> a_list[4:4] = ['e']
>>> a_list
['a', 'b', 'c', 'd', 'e', 'f']>>> a = ['one', 'two', 'three']
>>> del a[1]
>>> a
['one', 'three']>>> a_list = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del a_list[1:5]
>>> a_list
['a', 'f']>>> mylist = []
>>> mylist.append('this')
>>> mylist
['this']
>>> mylist.append('that')
>>> mylist
['this', 'that']
>>> mylist.insert(1, 'thing')
>>> mylist
['this', 'thing', 'that']
>>> mylist.sort()
>>> mylist
['that', 'thing', 'this']
>>> mylist.remove('thing')
>>> mylist
['that', 'this']
>>> mylist.reverse()
>>> mylist
['this', 'that']>>> a = [1, 2, 3]
>>> b = [1, 2, 3]>>> a == b
True>>> a is b
False>>> a = [1, 2, 3]
>>> b = a
>>> a is b
True>>> b[0] = 5
>>> a
[5, 2, 3]>>> a = [1, 2, 3]
>>> b = a[:]
>>> b
[1, 2, 3]>>> b[0] = 5
>>> a
[1, 2, 3]>>> nested = ["hello", 2.0, 5, [10, 20]]>>> elem = nested[3]
>>> elem[0]
10>>> nested[3][1]
20>>> list("Crunchy Frog")
['C', 'r', 'u', 'n', 'c', 'h', 'y', ' ', 'F', 'r', 'o', 'g']>>> "Crunchy frog covered in dark, bittersweet chocolate".split()
['Crunchy', 'frog', 'covered', 'in', 'dark,', 'bittersweet', 'chocolate']>>> "Crunchy frog covered in dark, bittersweet chocolate".split('o')
['Crunchy fr', 'g c', 'vered in dark, bittersweet ch', 'c', 'late']>>> ' '. join(['crunchy', 'raw', 'unboned', 'real', 'dead', 'frog'])
'crunchy raw unboned real dead frog'>>> '**'.join(['crunchy', 'raw', 'unboned', 'real', 'dead', 'frog'])
'crunchy**raw**unboned**real**dead**frog'>>> ''.join(['crunchy', 'raw', 'unboned', 'real', 'dead', 'frog'])
'crunchyrawunbonedrealdeadfrog'temp = a
a = b
b = tempa, b = b, a>>> a, b, c, d = 1, 2, 3
ValueError: need more than 3 values to unpack>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>>>> type(true)
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
NameError: name 'true' is not defined>>> 5 == 5
True
>>> 5 == 6
Falsex != y # x is not equal to y
x > y # x is greater than y
x < y # x is less than y
x >= y # x is greater than or equal to y
x <= y # x is less than or equal to y>>> 5 > 4 and 8 == 2 * 4
True
>>> True and False
False
>>> False or True
True>>> numbers = (5, 11, 13, 24)
>>> numbers[4] % 2 == 0Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: tuple index out of range
>>>>>> len(numbers) >= 5 and numbers[4] % 2 == 0
False>>> 'A' and 'apples'
'apples'
>>> '' and 'apples'
''
>>> '' or [5, 6]
[5, 6]
>>> ('a', 'b', 'c') or [5, 6]
('a', 'b', 'c')>>> [1, 2, 3]
[1, 2, 3]
>>> ['cat', 'bat', 'rat', 'elephant']
['cat', 'bat', 'rat', 'elephant']
>>> ['hello', 3.1415, True, None, 42]
['hello', 3.1415, True, None, 42]
➊ >>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam
['cat', 'bat', 'rat', 'elephant']
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0]
'cat'
>>> spam[1]
'bat'
>>> spam[2]
'rat'
>>> spam[3]
'elephant'
>>> ['cat', 'bat', 'rat', 'elephant'][3]
'elephant'
➊ >>> 'Hello, ' + spam[0]
➋ 'Hello, cat'
>>> 'The ' + spam[1] + ' ate the ' + spam[0] + '.'
'The bat ate the cat.'>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[10000]
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
spam[10000]
IndexError: list index out of range
>>> spam = [['cat', 'bat'], [10, 20, 30, 40, 50]]
>>> spam[0]
['cat', 'bat']
>>> spam[0][1]
'bat'
>>> spam[1][4]
50
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[-1]
'elephant'
>>> spam[-3]
'bat'
>>> 'The ' + spam[-1] + ' is afraid of the ' + spam[-3] + '.'
'The elephant is afraid of the bat.'>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[0:4]
['cat', 'bat', 'rat', 'elephant']
>>> spam[1:3]
['bat', 'rat']
>>> spam[0:-1]
['cat', 'bat', 'rat']
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[:2]
['cat', 'bat']
>>> spam[1:]
['bat', 'rat', 'elephant']
>>> spam[:]
['cat', 'bat', 'rat', 'elephant']
>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> spam[1] = 'aardvark'
>>> spam
['cat', 'aardvark', 'rat', 'elephant']
>>> spam[2] = spam[1]
>>> spam
['cat', 'aardvark', 'aardvark', 'elephant']
>>> spam[-1] = 12345
>>> spam
['cat', 'aardvark', 'aardvark', 12345]
>>> [1, 2, 3] + ['A', 'B', 'C']
[1, 2, 3, 'A', 'B', 'C']
>>> ['X', 'Y', 'Z'] * 3
['X', 'Y', 'Z', 'X', 'Y', 'Z', 'X', 'Y', 'Z']
>>> spam = [1, 2, 3]
>>> spam = spam + ['A', 'B', 'C']
>>> spam
[1, 2, 3, 'A', 'B', 'C']>>> spam = ['cat', 'bat', 'rat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat', 'elephant']
>>> del spam[2]
>>> spam
['cat', 'bat']
catName1 = 'Zophie'
catName2 = 'Pooka'
catName3 = 'Simon'
catName4 = 'Lady Macbeth'
catName5 = 'Fat-tail'
catName6 = 'Miss Cleo'
print('Enter the name of cat 1:')
catName1 = input()
print('Enter the name of cat 2:')
catName2 = input()
print('Enter the name of cat 3:')
catName3 = input()
print('Enter the name of cat 4:')
catName4 = input()
print('Enter the name of cat 5:')
catName5 = input()
print('Enter the name of cat 6:')
catName6 = input()
print('The cat names are:')
print(catName1 + ' ' + catName2 + ' ' + catName3 + ' ' + catName4 + ' ' +
catName5 + ' ' + catName6)
catNames = []
while True:
print('Enter the name of cat ' + str(len(catNames) + 1) +
' (Or enter nothing to stop.):')
name = input()
if name == '':
break
catNames = catNames + [name] # list concatenation
print('The cat names are:')
for name in catNames:
print(' ' + name)
>>> 'howdy' in ['hello', 'hi', 'howdy', 'heyas']
True
>>> spam = ['hello', 'hi', 'howdy', 'heyas']
>>> 'cat' in spam
False
>>> 'howdy' not in spam
False
>>> 'cat' not in spam
True
# Conway's Game of Life
import random, time, copy
WIDTH = 60
HEIGHT = 20
# Create a list of list for the cells:
nextCells = []
for x in range(WIDTH):
column = [] # Create a new column.
for y in range(HEIGHT):
if random.randint(0, 1) == 0:
column.append('#') # Add a living cell.
else:
column.append(' ') # Add a dead cell.
nextCells.append(column) # nextCells is a list of column lists.
while True: # Main program loop.
print('\n\n\n\n\n') # Separate each step with newlines.
currentCells = copy.deepcopy(nextCells)
# Print currentCells on the screen:
for y in range(HEIGHT):
for x in range(WIDTH):
print(currentCells[x][y], end='') # Print the # or space.
print() # Print a newline at the end of the row.
# Calculate the next step's cells based on current step's cells:
for x in range(WIDTH):
for y in range(HEIGHT):
# Get neighboring coordinates:
# `% WIDTH` ensures leftCoord is always between 0 and WIDTH - 1
leftCoord = (x - 1) % WIDTH
rightCoord = (x + 1) % WIDTH
aboveCoord = (y - 1) % HEIGHT
belowCoord = (y + 1) % HEIGHT
# Count number of living neighbors:
numNeighbors = 0
if currentCells[leftCoord][aboveCoord] == '#':
numNeighbors += 1 # Top-left neighbor is alive.
if currentCells[x][aboveCoord] == '#':
numNeighbors += 1 # Top neighbor is alive.
if currentCells[rightCoord][aboveCoord] == '#':
numNeighbors += 1 # Top-right neighbor is alive.
if currentCells[leftCoord][y] == '#':
numNeighbors += 1 # Left neighbor is alive.
if currentCells[rightCoord][y] == '#':
numNeighbors += 1 # Right neighbor is alive.
if currentCells[leftCoord][belowCoord] == '#':
numNeighbors += 1 # Bottom-left neighbor is alive.
if currentCells[x][belowCoord] == '#':
numNeighbors += 1 # Bottom neighbor is alive.
if currentCells[rightCoord][belowCoord] == '#':
numNeighbors += 1 # Bottom-right neighbor is alive.
# Set cell based on Conway's Game of Life rules:
if currentCells[x][y] == '#' and (numNeighbors == 2 or
numNeighbors == 3):
# Living cells with 2 or 3 neighbors stay alive:
nextCells[x][y] = '#'
elif currentCells[x][y] == ' ' and numNeighbors == 3:
# Dead cells with 3 neighbors become alive:
nextCells[x][y] = '#'
else:
# Everything else dies or stays dead:
nextCells[x][y] = ' '
time.sleep(1) # Add a 1-second pause to reduce flickering.
Let’s look at this code line by line, starting at the top.
# Conway's Game of Life
import random, time, copy
WIDTH = 60
HEIGHT = 20
First we import modules that contain functions we’ll need, namely the random.randint(), time.sleep(), and copy.deepcopy() functions.
# Create a list of list for the cells:
nextCells = []
for x in range(WIDTH):
column = [] # Create a new column.
for y in range(HEIGHT):
if random.randint(0, 1) == 0:
column.append('#') # Add a living cell.
else:
column.append(' ') # Add a dead cell.
nextCells.append(column) # nextCells is a list of column lists.
The very first step of our cellular automata will be completely random. We need to create a list of lists data structure to store the '#' and ' ' strings that represent a living or dead cell, and their place in the list of lists reflects their position on the screen. The inner lists each represent a column of cells. The random.randint(0, 1) call gives an even 50/50 chance between the cell starting off alive or dead.
We put this list of lists in a variable called nextCells, because the first step in our main program loop will be to copy nextCells into currentCells. For our list of lists data structure, the x-coordinates start at 0 on the left and increase going right, while the y-coordinates start at 0 at the top and increase going down. So nextCells[0][0] will represent the cell at the top left of the screen, while nextCells[1][0] represents the cell to the right of that cell and nextCells[0][1] represents the cell beneath it.
while True: # Main program loop.
print('\n\n\n\n\n') # Separate each step with newlines.
currentCells = copy.deepcopy(nextCells)
Each iteration of our main program loop will be a single step of our cellular automata. On each step, we’ll copy nextCells to currentCells, print currentCells on the screen, and then use the cells in currentCells to calculate the cells in nextCells.
# Print currentCells on the screen:
for y in range(HEIGHT):
for x in range(WIDTH):
print(currentCells[x][y], end='') # Print the # or space.
print() # Print a newline at the end of the row.
These nested for loops ensure that we print a full row of cells to the screen, followed by a newline character at the end of the row. We repeat this for each row in nextCells.
# Calculate the next step's cells based on current step's cells:
for x in range(WIDTH):
for y in range(HEIGHT):
# Get neighboring coordinates:
# `% WIDTH` ensures leftCoord is always between 0 and WIDTH - 1
leftCoord = (x - 1) % WIDTH
rightCoord = (x + 1) % WIDTH
aboveCoord = (y - 1) % HEIGHT
belowCoord = (y + 1) % HEIGHT
"""
Strings are an ordered collection of unicode characters that cannot be
modified at runtime. This module shows how strings are created, iterated,
accessed and concatenated.
"""
# Module-level constants
_DELIMITER = " | "
def main():
# Strings are some of the most robust data structures around
content = "Ultimate Python study guide"
# We can compute the length of a string just like all other data structures
assert len(content) > 0
# We can use range slices to get substrings from a string
assert content[:8] == "Ultimate"
assert content[9:15] == "Python"
assert content[::-1] == "ediug yduts nohtyP etamitlU"
# Like tuples, we cannot change the data in a string. However, we can
# create a new string from existing strings
new_content = f"{content.upper()}{_DELIMITER}{content.lower()}"
assert _DELIMITER in new_content
# We can split one string into a list of strings
split_content = new_content.split(_DELIMITER)
assert isinstance(split_content, list)
assert len(split_content) == 2
assert all(isinstance(item, str) for item in split_content)
# A two-element list can be decomposed as two variables
upper_content, lower_content = split_content
assert upper_content.isupper() and lower_content.islower()
# Notice that the data in `upper_content` and `lower_content` exists
# in the `new_content` variable as expected
assert upper_content in new_content
assert new_content.startswith(upper_content)
assert lower_content in new_content
assert new_content.endswith(lower_content)
# Notice that `upper_content` and `lower_content` are smaller in length
# than `new_content` and have the same length as the original `content`
# they were derived from
assert len(upper_content) < len(new_content)
assert len(lower_content) < len(new_content)
assert len(upper_content) == len(lower_content) == len(content)
# We can also join `upper_content` and `lower_content` back into one
# string with the same contents as `new_content`. The `join` method is
# useful for joining an arbitrary amount of text items together
joined_content = _DELIMITER.join(split_content)
assert isinstance(joined_content, str)
assert new_content == joined_content
if __name__ == "__main__":
main()
The zipped result is : {('Shambhavi', 3, 60), ('Astha', 2, 70),
('Manjeet', 4, 40), ('Nikhil', 1, 50)}# Python code to demonstrate the working of
# unzip
# initializing lists
name = [ "Manjeet", "Nikhil", "Shambhavi", "Astha" ]
roll_no = [ 4, 1, 3, 2 ]
marks = [ 40, 50, 60, 70 ]
# using zip() to map values
mapped = zip(name, roll_no, marks)
# converting values to print as list
mapped = list(mapped)
# printing resultant values
print ("The zipped result is : ",end="")
print (mapped)
print("\n")
# unzipping values
namz, roll_noz, marksz = zip(*mapped)
print ("The unzipped result: \n",end="")
# printing initial lists
print ("The name list is : ",end="")
print (namz)
print ("The roll_no list is : ",end="")
print (roll_noz)
print ("The marks list is : ",end="")
print (marksz)
>>> type("Hello, World!")
<class 'str'>
>>> type(17)
<class 'int'>>>> type(3.2)
<class 'float'>>>> type("17")
<class 'str'>
>>> type("3.2")
<class 'str'>>>> 42000
42000
>>> 42,000
(42, 0)>>> type('This is a string.')
<class 'str'>
>>> type("And so is this.")
<class 'str'>
>>> type("""and this.""")
<class 'str'>
>>> type('''and even this...''')
<class 'str'>>>> print('''"Oh no," she exclaimed, "Ben's bike is broken!"''')
"Oh no," she exclaimed, "Ben's bike is broken!"
>>>>>> message = """This message will
... span several
... lines."""
>>> print(message)
This message will
span several
lines.
>>>>>> 'This is a string.'
'This is a string.'
>>> """And so is this."""
'And so is this.'>>> print("Line 1\n\n\nLine 5")
Line 1
Line 5
>>>>>> message = "What's up, Doc?"
>>> n = 17
>>> pi = 3.14159>>> message
"What's up, Doc?"
>>> pi
3.14159
>>> n
17
>>> print(message)
What's up, Doc?>>> type(message)
<class 'str'>
>>> type(n)
<class 'int'>
>>> type(pi)
<class 'float'>>>> day = "Thursday"
>>> day
'Thursday'
>>> day = "Friday"
>>> day
'Friday'
>>> day = 21
>>> day
21>>> n = 17
>>> n = n + 1
>>> n
18>>> 17 = n>>> 76trombones = "big parade"
SyntaxError: invalid syntax
>>> more$ = 1000000
SyntaxError: invalid syntax
>>> class = "Computer Science 101"
SyntaxError: invalid syntax>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class',
'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for',
'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not',
'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']>>> 1 + 1
2
>>> len('hello')
5>>> 17
17
>>> y = 3.14
>>> x = len('hello')
>>> x
5
>>> y
3.1420 + 32 hour - 1 hour * 60 + minute minute / 60 5 ** 2
(5 + 9) * (15 - 7)>>> 2 ** 3
8
>>> 3 ** 2
9>>> minutes = 645
>>> hours = minutes / 60
>>> hours
10.75>>> 7 / 4
1.75
>>> 7 // 4
1
>>> minutes = 645
>>> hours = minutes // 60
>>> hours
10>>> 7 // 3 # integer division operator
2
>>> 7 % 3
1total_secs = int(input("How many seconds, in total? "))
hours = total_secs // 3600
secs_still_remaining = total_secs % 3600
minutes = secs_still_remaining // 60
secs_finally_remaining = secs_still_remaining % 60
print(hours, ' hrs ', minutes, ' mins ', secs_finally_remaining, ' secs')>>> 2 ** 3 ** 2 # the right-most ** operator gets done first!
512
>>> (2 ** 3) ** 2 # use parentheses to force the order you want!
64message - 1 "Hello" / 123 message * "Hello" "15" + 2fruit = "banana"
baked_good = " nut bread"
print(fruit + baked_good)>>> int(3.14)
3
>>> int(3.9999) # This doesn't round to the closest int!
3
>>> int(3.0)
3
>>> int(-3.999) # Note that the result is closer to zero
-3
>>> int(minutes/60)
10
>>> int("2345") # parse a string to produce an int
2345
>>> int(17) # int even works if its argument is already an int
17
>>> int("23 bottles")
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '23 bottles'>>> float(17)
17.0
>>> float("123.45")
123.45>>> str(17)
'17'
>>> str(123.45)
'123.45'name = input("Please enter your name: ")response = input("What is your radius? ")
r = float(response)
area = 3.14159 * r ** 2
print("The area is ", area)r = float(input("What is your radius? "))
print("The area is ", 3.14159 * r ** 2)print("The area is ", 3.14159 * float(input("What is your radius? ")) ** 2)>>> print("I am", 12 + 9, "years old.")
I am 21 years old.
>>>>>> print('a', 'b', 'c', 'd')
a b c d
>>> print('a', 'b', 'c', 'd', sep='##', end='!!')
a##b##c##d!!>>>n = n + 1
format method for stringsopen functionrepr() and eval() functionsf, as we did in line 11 of the code above, or perhaps we’ll ask integer numbers to be converted to hexadecimal using x)>>> eng2sp = {}
>>> type(eng2sp)
<class 'dict'>
>>> eng2sp['one'] = 'uno'
>>> eng2sp['two'] = 'dos'
>>> eng2sp['three'] = 'tres'>>> print(eng2sp)
{'three': 'tres', 'one': 'uno', 'two': 'dos'}>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}>>> eng2sp['two']
'dos'>>> inventory = {'apples': 430, 'bananas': 312, 'oranges': 525, 'pears': 217}
>>> print(inventory)
{'apples': 430, 'bananas': 312, 'pears': 217, 'oranges': 525}>>> del inventory['pears']
>>> print(inventory)
{'apples': 430, 'bananas': 312, 'oranges': 525}>>> inventory['pears'] = 0
>>> print(inventory)
{'apples': 430, 'bananas': 312, 'pears': 0, 'oranges': 525}>>> len(inventory)
4>>> 'pears' in inventory
True
>>> 'blueberries' in inventory
False>>> inventory['blueberries']
Traceback (most recent call last):
File "", line 1, in <module>
KeyError: 'blueberries'
>>>>>> inventory.get('blueberries', 0)
0
>>> inventory.get('bananas', 0)
312>>> sorted(inventory)
['apples', 'bananas', 'oranges', 'pears']>>> opposites = {'up': 'down', 'right': 'wrong', 'true': 'false'}
>>> an_alias = opposites
>>> a_copy = opposites.copy()>>> an_alias['right'] = 'left'
>>> opposites['right']
'left'>>> a_copy['right'] = 'privilege'
>>> opposites['right']
'left'>>> what_am_i = {'apples': 32, 'bananas': 47, 'pears': 17}
>>> type(what_am_i)
<class 'dict'>
>>> what_am_i = {'apples', 'bananas', 'pears'}
>>> type(what_am_i)
<class 'set'>>>> what_am_i = {}
>>> type(what_am_i)
<class 'dict'>
>>> what_am_i = set()
>>> type(what_am_i)
<class 'set'>
>>> what_am_i
set()>>> set_of_numbers = {1, 2, 3, 4}
>>> set_of_numbers
{1, 2, 3, 4}
>>> set_of_numbers.add(5)
>>> set_of_numbers
{1, 2, 3, 4, 5}
>>> 3 in set_of_numbers
True
>>> 6 in set_of_numbers
False>>> list_of_numbers = [1, 2, 1, 3, 4, 8, 11, 4, 5, 8]
>>> set(list_of_numbers)
{1, 2, 3, 4, 5, 8, 11}>>> "His name is {0}!".format("Arthur")
'His name is Arthur!'
>>> name = "Alice"
>>> age = 10
>>> "I am {0} and I am {1} years old.".format(name, age)
'I am Alice and I am 10 years old.'
>>> n1 = 4
>>> n2 = 5
>>> "2 ** 10 = {0} and {1} * {2} = {3:f}".format(2 ** 10, n1, n2, n1 * n2)
'2 ** 10 = 1024 and 4 * 5 = 20.000000'letter = """
Dear {0} {2},
{0}, I have an interesting money-making proposition for you!
If you deposit $10 million into my bank account, I can
double your money ...
"""
print(letter.format("Paris", "Whitney", "Hilton"))
print(letter.format("Bill", "Henry", "Gates"))Dear Paris Hilton,
Paris, I have an interesting money-making proposition for you!
If you deposit $10 million into my bank account, I can
double your money ...
Dear Bill Gates,
Bill, I have an interesting money-making proposition for you!
If you deposit $10 million into my bank account I can,
double your money ...>>> "hello {3}".format("Dave")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: tuple index out of range>>> s = "'{cat}'ll {verb1} me very much {time}, I should {verb2}!'"
>>> s.format(verb1="miss", cat="Dinah", time="to-night", verb2="think")
"'Dinah'll miss me very much to-night, I should think!'""<FORMAT>" % (<VALUES>)>>> "His name is %s." % "Arthur"
'His name is Arthur.'
>>> name = "Alice"
>>> age = 10
>>> "I am %s and I am %d years old." % (name, age)
'I am Alice and I am 10 years old.'
>>> n1 = 4
>>> n2 = 5
>>> "2**10 = %d and %d * %d = %f" % (2**10, n1, n2, n1 * n2)
'2 ** 10 = 1024 and 4 * 5 = 20.000000'
>>>>>> myfile = open('test.txt', 'w')
>>> myfile.write('My first file written from Python\n')
34
>>> myfile.write('---------------------------------\n')
34
>>> myfile.write('Hello, world!')
13
>>> myfile.close()
>>> myfile = open('test.txt', 'r')
>>> contents = myfile.read()
>>> myfile.close()
>>> print(contents)
My first file written from Python
---------------------------------
Hello, world!>>> myfile = open('test.txt', 'a')
>>> myfile.write('\nOoops, I forgot to add this line ;-)')
37
>>> myfile.close()
>>> myfile = open('test.txt', 'r')
>>> print(myfile.read())
My first file written from Python
---------------------------------
Hello, world!
Ooops, I forgot to add this line ;-)
>>>>>> f = open('wharrah.txt', 'r')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'wharrah.txt'
>>>try:
f = open('thefile.txt', 'r')
mydata = f.read()
f.close()
except IOError:
mydata = ''f = open('test.txt', 'r')
while True: # keep reading forever
theline = f.readline() # try to read next line
if len(theline) == 0: # if there are no more lines
break # leave the loop
# Now process the line we've just read
print(theline, end='')
f.close()f1 = open('friends.txt', 'r')
friends_list = f.readlines()
f1.close()
friends_list.sort()
f2 = open('sortedfriends.txt', 'w')
for friend in friends_list:
f2.write(v)
f2.close()infile = open(oldfile, 'r')
outfile = open(newfile, 'w')
while True:
text = infile.readline()
if len(text) == 0:
break
if text[0] == '#':
continue
# put any more processing logic here
outfile.write(text)
infile.close()
outfile.close()>>> mylist = [1, 2, 'buckle', 'my', 'shoe']
>>> type(mylist)
<class 'list'>
>>> repr(mylist)
"[1, 2, 'buckle', 'my', 'shoe']"
>>> s = repr(mylist)
>>> s
"[1, 2, 'buckle', 'my', 'shoe']"
>>> type(s)
<class 'str'>
>>> eval(s)
[1, 2, 'buckle', 'my', 'shoe']
>>> thing = eval(s)
>>> thing
[1, 2, 'buckle', 'my', 'shoe']
>>> type(thing)
<class 'list'>
>>># seqtools.py
#
def remove_at(pos, seq):
return seq[:pos] + seq[pos+1:]>>> from seqtools import remove_at
>>> s = "A string!"
>>> remove_at(4, s)
'A sting!'>>> import seqtools
>>> s = "A string!"
>>> seqtools.remove_at(4, s)
'A sting!'# module1.py
question = "What is the meaning of life, the Universe, and everything?"
answer = 42# module2.py
question = "What is your quest?"
answer = "To seek the holy grail.">>> import module1
>>> import module2
>>> print module1.question
What is the meaning of life, the Universe, and everything?
>>> print module2.question
What is your quest?
>>> print module1.answer
42
>>> print module2.answer
To seek the holy grail.
>>>def f():
n = 7
print("printing n inside of f: {0}".format(n))
def g():
n = 42
print("printing n inside of g: {0}".format(n))
n = 11
print("printing n before calling f: {0}".format(n))
f()
print("printing n after calling f: {0}".format(n))
g()
print("printing n after calling g: {0}".format(n))printing n before calling f: 11
printing n inside of f: 7
printing n after calling f: 11
printing n inside of g: 42
printing n after calling g: 11>>> import string
>>> string.capitalize('maryland')
'Maryland'
>>> string.capwords("what's all this, then, amen?")
"What's All This, Then, Amen?"
>>> string.center('How to Center Text Using Python', 70)
' How to Center Text Using Python '
>>> string.upper('angola')
'ANGOLA'
>>>def print_thrice(thing):
print thing, thing, thing
n = 42
s = "And now for something completely different..."$ ls
tryme.py
$ python
>>>>>> n
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'n' is not defined
>>> print_thrice("ouch!")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'print_thrice' is not defined>>> from tryme import *
>>> n
42
>>> s
'And now for something completely different...'
>>> print_thrice("Yipee!")
Yipee! Yipee! Yipee!
>>># mymodule.py file
def generate_full_name(firstname, lastname):
return firstname + ' ' + lastname# main.py file
import mymodule
print(mymodule.generate_full_name('Asabeneh', 'Yetayeh')) # Asabeneh Yetayeh# main.py file
from mymodule import generate_full_name, sum_two_nums, person, gravity
print(generate_full_name('Asabneh','Yetayeh'))
print(sum_two_nums(1,9))
mass = 100;
weight = mass * gravity
print(weight)
print(person['firstname'])# main.py file
from mymodule import generate_full_name as fullname, sum_two_nums as total, person as p, gravity as g
print(fullname('Asabneh','Yetayeh'))
print(total(1, 9))
mass = 100;
weight = mass * g
print(weight)
print(p)
print(p['firstname'])# import the module
import os
# Creating a directory
os.mkdir('directory_name')
# Changing the current directory
os.chdir('path')
# Getting current working directory
os.getcwd()
# Removing directory
os.rmdir()import sys
#print(sys.argv[0], argv[1],sys.argv[2]) # this line would print out: filename argument1 argument2
print('Welcome {}. Enjoy {} challenge!'.format(sys.argv[1], sys.argv[2]))python script.py Asabeneh 30DaysOfPythonWelcome Asabeneh. Enjoy 30DayOfPython challenge!# to exit sys
sys.exit()
# To know the largest integer variable it takes
sys.maxsize
# To know environment path
sys.path
# To know the version of python you are using
sys.versionfrom statistics import * # importing all the statistics modules
ages = [20, 20, 4, 24, 25, 22, 26, 20, 23, 22, 26]
print(mean(ages)) # ~22.9
print(median(ages)) # 23
print(mode(ages)) # 20
print(stdev(ages)) # ~2.3import math
print(math.pi) # 3.141592653589793, pi constant
print(math.sqrt(2)) # 1.4142135623730951, square root
print(math.pow(2, 3)) # 8.0, exponential function
print(math.floor(9.81)) # 9, rounding to the lowest
print(math.ceil(9.81)) # 10, rounding to the highest
print(math.log10(100)) # 2, logarithm with 10 as basefrom math import pi
print(pi)from math import pi, sqrt, pow, floor, ceil, log10
print(pi) # 3.141592653589793
print(sqrt(2)) # 1.4142135623730951
print(pow(2, 3)) # 8.0
print(floor(9.81)) # 9
print(ceil(9.81)) # 10
print(math.log10(100)) # 2from math import *
print(pi) # 3.141592653589793, pi constant
print(sqrt(2)) # 1.4142135623730951, square root
print(pow(2, 3)) # 8.0, exponential
print(floor(9.81)) # 9, rounding to the lowest
print(ceil(9.81)) # 10, rounding to the highest
print(math.log10(100)) # 2from math import pi as PI
print(PI) # 3.141592653589793import string
print(string.ascii_letters) # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.digits) # 0123456789
print(string.punctuation) # !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~from random import random, randint
print(random()) # it doesn't take any arguments; it returns a value between 0 and 0.9999
print(randint(5, 20)) # it returns a random integer number between [5, 20] inclusive print(random_user_id());
'1ee33d'print(user_id_gen_by_user()) # user input: 5 5
#output:
#kcsy2
#SMFYb
#bWmeq
#ZXOYh
#2Rgxf
print(user_id_gen_by_user()) # 16 5
#1GCSgPLMaBAVQZ26
#YD7eFwNQKNs7qXaT
#ycArC5yrRupyG00S
#UbGxOFI7UXSWAyKN
#dIV0SSUTgAdKwStrprint(rgb_color_gen())
# rgb(125,244,255) - the output should be in this form generate_colors('hexa', 3) # ['#a3e12f','#03ed55','#eb3d2b']
generate_colors('hexa', 1) # ['#b334ef']
generate_colors('rgb', 3) # ['rgb(5, 55, 175','rgb(50, 105, 100','rgb(15, 26, 80']
generate_colors('rgb', 1) # ['rgb(33,79, 176)']and, or, notprintf-style String Formattingprintf-style Bytes FormattingselfTimesclass SimpleGradebook:
def __init__(self):
self._grades = {}
def add_student(self, name):
self._grades[name] = []
def report_grade(self, name, score):
self._grades[name].append(score)
def average_grade(self, name):
grades = self._grades[name]
return sum(grades) / len(grades)book = SimpleGradebook()
book.add_student('Isaac Newton')
book.report_grade('Isaac Newton', 90)
book.report_grade('Isaac Newton', 95)
book.report_grade('Isaac Newton', 85)
print(book.average_grade('Isaac Newton'))
>>>
90.0>>> fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
>>> fruits.count('apple')
2
>>> fruits.count('tangerine')
0
>>> fruits.index('banana')
3
>>> fruits.index('banana', 4) # Find next banana starting a position 4
6
>>> fruits.reverse()
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange']
>>> fruits.append('grape')
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange', 'grape']
>>> fruits.sort()
>>> fruits
['apple', 'apple', 'banana', 'banana', 'grape', 'kiwi', 'orange', 'pear']
>>> fruits.pop()
'pear'>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])>>> squares = []
>>> for x in range(10):
... squares.append(x**2)
...
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]squares = list(map(lambda x: x**2, range(10)))squares = [x**2 for x in range(10)]>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]>>> combs = []
>>> for x in [1,2,3]:
... for y in [3,1,4]:
... if x != y:
... combs.append((x, y))
...
>>> combs
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]>>> vec = [-4, -2, 0, 2, 4]
>>> # create a new list with the values doubled
>>> [x*2 for x in vec]
[-8, -4, 0, 4, 8]
>>> # filter the list to exclude negative numbers
>>> [x for x in vec if x >= 0]
[0, 2, 4]
>>> # apply a function to all the elements
>>> [abs(x) for x in vec]
[4, 2, 0, 2, 4]
>>> # call a method on each element
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
>>> # create a list of 2-tuples like (number, square)
>>> [(x, x**2) for x in range(6)]
[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
>>> # the tuple must be parenthesized, otherwise an error is raised
>>> [x, x**2 for x in range(6)]
File "<stdin>", line 1, in <module>
[x, x**2 for x in range(6)]
^
SyntaxError: invalid syntax
>>> # flatten a list using a listcomp with two 'for'
>>> vec = [[1,2,3], [4,5,6], [7,8,9]]
>>> [num for elem in vec for num in elem]
[1, 2, 3, 4, 5, 6, 7, 8, 9]>>> from math import pi
>>> [str(round(pi, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]>>> list(zip(*matrix))
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]>>> del a>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
>>> # Tuples are immutable:
... t[0] = 88888
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> # but they can contain mutable objects:
... v = ([1, 2, 3], [3, 2, 1])
>>> v
([1, 2, 3], [3, 2, 1])>>> empty = ()
>>> singleton = 'hello', # <-- note trailing comma
>>> len(empty)
0
>>> len(singleton)
1
>>> singleton
('hello',)>>> x, y, z = t>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'jack': 4098, 'sape': 4139, 'guido': 4127}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'jack': 4098, 'guido': 4127, 'irv': 4127}
>>> list(tel)
['jack', 'guido', 'irv']
>>> sorted(tel)
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
False>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'guido': 4127, 'jack': 4098}>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'guido': 4127, 'jack': 4098}>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for i in sorted(basket):
... print(i)
...
apple
apple
banana
orange
orange
pear>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear>>> import math
>>> raw_data = [56.2, float('NaN'), 51.7, 55.3, 52.5, float('NaN'), 47.8]
>>> filtered_data = []
>>> for value in raw_data:
... if not math.isnan(value):
... filtered_data.append(value)
...
>>> filtered_data
[56.2, 51.7, 55.3, 52.5, 47.8]>>> string1, string2, string3 = '', 'Trondheim', 'Hammer Dance'
>>> non_null = string1 or string2 or string3
>>> non_null
'Trondheim'(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)not (a == b)a == not bx = m / n is a nonnegative rational number and n is divisible by P (but m is not) then n has no inverse modulo P and the rule above doesn’t apply; in this case define hash(x) to be the constant value sys.hash_info.inf.[x for x in iterable]a, b, c or (a, b, c)"""Three double quotes"""b"""3 double quotes"""set('foobar')set(['a', 'b', 'foo'])
# Set the tuple1 variable to an empty tuple
tuple1 = ()
# Check if the tuple is initialized properly
print(type(tuple1))
# Output : <class 'tuple'># Set the tuple2 variable to an empty tuple by using the tuple() method
tuple2 = tuple()
# Check if the tuple is initialized properly
print(type(tuple2))
# Output : <class 'tuple'># tuple3 consists of values 40, 50, 60
tuple3 = (40, 50, 60)
# tuples can also consist of different datatypes
tuple4 = (45, "55", "Hello World", True, 42.6)
# we can also create a tuple of lists
tuple5 = ([10, 20], [30, 40], [50, 60])tuple1 = (0, 1, 2, 3)
print(tuple1[0]) # Output: 0
print(tuple1[1]) # Output: 1tuple1 = (30, 40, 50, 60)
print(tuple1[-1]) # Output: 60
print(tuple1[-3]) # Output: 40tuple1 = (1, 2, 3, 5, 8, 13)
print(tuple1[0:3]) # Output: (1, 2, 3)
print(tuple1[4:]) # Output: (8, 13)tuple1 = (2000, 3000, 4000)
tuple1[1] = 1000Traceback (most recent call last):
File "main.py", line 3 in <module>
tuple1[1] = 1000
TypeError: 'tuple' object does not support item assignmenttuple1 = ([10, 20], [30, 40], [50, 60])
tuple1[1][0] = 70
print(tuple1) # Output: ([10, 20], [70, 40], [50, 60])tuple1 = ([10, 20], [30, 40], [50, 60])
tuple2 = ([100, 200], [300, 400])
# Creating a new tuple from tuple1 and tuple2
tuple3 = tuple1 + tuple2
print(tuple3) # Output: ([10, 20], [30, 40], [50, 60], [100, 200], [300, 400])def cmp(t1, t2):
return bool(t1 > t2) - bool(t1 < t2)
"""
When both tuples are equal,
bool(t1 > t2) = 0
bool(t1 < t2) = 0
Therefore, 0 - 0 = 0
When both tuple1 > tuple2,
bool(t1 > t2) = 1
bool(t1 < t2) = 0
Therefore, 1 - 0 = 1
When both tuple2 > tuple1,
bool(t1 > t2) = 0
bool(t1 < t2) = 1
Therefore, 0 - 1 = -1
"""
tuple1 = (100, 200)
tuple2 = (300, 400)
print(cmp(tuple1, tuple2))
# Output: -1
print(cmp(tuple2, tuple1))
# Output: 1
tuple1 = (100, 200)
tuple2 = (100, 200)
print(cmp(tuple2, tuple1))
# Output: 0
tuple1 = (100, 300)
tuple2 = (200, 100)
print(cmp(tuple2, tuple1))
# Output: 1
# This is because the tuple comparison is done left to right. When tuple2[0] > tuple1[0], no further comparisons are made and the output is returned as zero. This is how the cmp() method works in Python.tuple1 = (10, 20, 30, 40, 50)
print(len(tuple1))
# Output: 5tuple1 = (3, 9, 1, 90, 200)
print(min(tuple1))
# Output: 1tuple1 = (3, 9, 1, 90, 200)
print(max(tuple1))
# Output: 200list1 = [23, 34, 45, 56]
print(tuple(list1))
# Output: (23, 34, 45, 56)tuple1 = (1, 24, 45, 54, 6, 34, 24)
print(tuple1.count(24))
# Output: 2tuple1 = (1, 24, 45, 54, 6, 34, 24)
print(tuple1.index(1))
# Output: 0tuple1 = (1, 24, 45, 54, 6, 34, 24)
print(tuple1.index(24, -1))
# Output: 6
# The second parameter specifies which index to start the search from
# -1 refers to the last element in the tuple, so it searches in reversetuple1 = (1, 24, 45, 54, 24, 6, 34, 24)
print(tuple1.index(24, 2, 5))
# Output: 4
# The second paramter is the starting index, third parameter is the ending index>>> n = -37
>>> bin(n)
'-0b100101'
>>> n.bit_length()
6def bit_length(self):
s = bin(self) # binary representation: bin(-37) --> '-0b100101'
s = s.lstrip('-0b') # remove leading zeros and minus sign
return len(s) # len('100101') --> 6>>> (1024).to_bytes(2, byteorder='big')
b'\x04\x00'
>>> (1024).to_bytes(10, byteorder='big')
b'\x00\x00\x00\x00\x00\x00\x00\x00\x04\x00'
>>> (-1024).to_bytes(10, byteorder='big', signed=True)
b'\xff\xff\xff\xff\xff\xff\xff\xff\xfc\x00'
>>> x = 1000
>>> x.to_bytes((x.bit_length() + 7) // 8, byteorder='little')
b'\xe8\x03'>>> int.from_bytes(b'\x00\x10', byteorder='big')
16
>>> int.from_bytes(b'\x00\x10', byteorder='little')
4096
>>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=True)
-1024
>>> int.from_bytes(b'\xfc\x00', byteorder='big', signed=False)
64512
>>> int.from_bytes([255, 0, 0], byteorder='big')
16711680>>> (-2.0).is_integer()
True
>>> (3.2).is_integer()
False[sign] ['0x'] integer ['.' fraction] ['p' exponent]>>> float.fromhex('0x3.a7p10')
3740.0>>> float.hex(3740.0)
'0x1.d380000000000p+11'import sys, math
def hash_fraction(m, n):
"""Compute the hash of a rational number m / n.
Assumes m and n are integers, with n positive.
Equivalent to hash(fractions.Fraction(m, n)).
"""
P = sys.hash_info.modulus
# Remove common factors of P. (Unnecessary if m and n already coprime.)
while m % P == n % P == 0:
m, n = m // P, n // P
if n % P == 0:
hash_value = sys.hash_info.inf
else:
# Fermat's Little Theorem: pow(n, P-1, P) is 1, so
# pow(n, P-2, P) gives the inverse of n modulo P.
hash_value = (abs(m) % P) * pow(n, P - 2, P) % P
if m < 0:
hash_value = -hash_value
if hash_value == -1:
hash_value = -2
return hash_value
def hash_float(x):
"""Compute the hash of a float x."""
if math.isnan(x):
return sys.hash_info.nan
elif math.isinf(x):
return sys.hash_info.inf if x > 0 else -sys.hash_info.inf
else:
return hash_fraction(*x.as_integer_ratio())
def hash_complex(z):
"""Compute the hash of a complex number z."""
hash_value = hash_float(z.real) + sys.hash_info.imag * hash_float(z.imag)
# do a signed reduction modulo 2**sys.hash_info.width
M = 2**(sys.hash_info.width - 1)
hash_value = (hash_value & (M - 1)) - (hash_value & M)
if hash_value == -1:
hash_value = -2
return hash_value>>> "gg" in "eggs"
True>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list(range(0, 30, 5))
[0, 5, 10, 15, 20, 25]
>>> list(range(0, 10, 3))
[0, 3, 6, 9]
>>> list(range(0, -10, -1))
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> list(range(0))
[]
>>> list(range(1, 0))
[]>>> r = range(0, 20, 2)
>>> r
range(0, 20, 2)
>>> 11 in r
False
>>> 10 in r
True
>>> r.index(10)
5
>>> r[5]
10
>>> r[:5]
range(0, 10, 2)
>>> r[-1]
18>>> str(b'Zoot!')
"b'Zoot!'">>> '01\t012\t0123\t01234'.expandtabs()
'01 012 0123 01234'
>>> '01\t012\t0123\t01234'.expandtabs(4)
'01 012 0123 01234'>>> 'Py' in 'Python'
True>>> "The sum of 1 + 2 is {0}".format(1+2)
'The sum of 1 + 2 is 3'>>> class Default(dict):
... def __missing__(self, key):
... return key
...
>>> '{name} was born in {country}'.format_map(Default(name='Guido'))
'Guido was born in country'>>> from keyword import iskeyword
>>> 'hello'.isidentifier(), iskeyword('hello')
True, False
>>> 'def'.isidentifier(), iskeyword('def')
True, True>>> 'BANANA'.isupper()
True
>>> 'banana'.isupper()
False
>>> 'baNana'.isupper()
False
>>> ' '.isupper()
False>>> ' spacious '.lstrip()
'spacious '
>>> 'www.example.com'.lstrip('cmowz.')
'example.com'>>> 'Arthur: three!'.lstrip('Arthur: ')
'ee!'
>>> 'Arthur: three!'.removeprefix('Arthur: ')
'three!'>>> 'TestHook'.removeprefix('Test')
'Hook'
>>> 'BaseTestCase'.removeprefix('Test')
'BaseTestCase'>>> 'MiscTests'.removesuffix('Tests')
'Misc'
>>> 'TmpDirMixin'.removesuffix('Tests')
'TmpDirMixin'>>> ' spacious '.rstrip()
' spacious'
>>> 'mississippi'.rstrip('ipz')
'mississ'>>> 'Monty Python'.rstrip(' Python')
'M'
>>> 'Monty Python'.removesuffix(' Python')
'Monty'>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']>>> '1 2 3'.split()
['1', '2', '3']
>>> '1 2 3'.split(maxsplit=1)
['1', '2 3']
>>> ' 1 2 3 '.split()
['1', '2', '3']>>> 'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines(keepends=True)
['ab c\n', '\n', 'de fg\r', 'kl\r\n']>>> "".splitlines()
[]
>>> "One line\n".splitlines()
['One line']>>> ''.split('\n')
['']
>>> 'Two lines\n'.split('\n')
['Two lines', '']>>> ' spacious '.strip()
'spacious'
>>> 'www.example.com'.strip('cmowz.')
'example'>>> comment_string = '#....... Section 3.2.1 Issue #32 .......'
>>> comment_string.strip('.#! ')
'Section 3.2.1 Issue #32'>>> 'Hello world'.title()
'Hello World'>>> "they're bill's friends from the UK".title()
"They'Re Bill'S Friends From The Uk">>> import re
>>> def titlecase(s):
... return re.sub(r"[A-Za-z]+('[A-Za-z]+)?",
... lambda mo: mo.group(0).capitalize(),
... s)
...
>>> titlecase("they're bill's friends.")
"They're Bill's Friends.">>> "42".zfill(5)
'00042'
>>> "-42".zfill(5)
'-0042'>>> print('%(language)s has %(number)03d quote types.' %
... {'language': "Python", "number": 2})
Python has 002 quote types.>>> bytes.fromhex('2Ef0 F1f2 ')
b'.\xf0\xf1\xf2'>>> b'\xf0\xf1\xf2'.hex()
'f0f1f2'>>> value = b'\xf0\xf1\xf2'
>>> value.hex('-')
'f0-f1-f2'
>>> value.hex('_', 2)
'f0_f1f2'
>>> b'UUDDLRLRAB'.hex(' ', -4)
'55554444 4c524c52 4142'>>> bytearray.fromhex('2Ef0 F1f2 ')
bytearray(b'.\xf0\xf1\xf2')>>> bytearray(b'\xf0\xf1\xf2').hex()
'f0f1f2'a = "abc"
b = a.replace("a", "f")a = b"abc"
b = a.replace(b"a", b"f")>>> b'TestHook'.removeprefix(b'Test')
b'Hook'
>>> b'BaseTestCase'.removeprefix(b'Test')
b'BaseTestCase'>>> b'MiscTests'.removesuffix(b'Tests')
b'Misc'
>>> b'TmpDirMixin'.removesuffix(b'Tests')
b'TmpDirMixin'>>> b'Py' in b'Python'
True>>> b'read this short text'.translate(None, b'aeiou')
b'rd ths shrt txt'>>> b' spacious '.lstrip()
b'spacious '
>>> b'www.example.com'.lstrip(b'cmowz.')
b'example.com'>>> b'Arthur: three!'.lstrip(b'Arthur: ')
b'ee!'
>>> b'Arthur: three!'.removeprefix(b'Arthur: ')
b'three!'>>> b' spacious '.rstrip()
b' spacious'
>>> b'mississippi'.rstrip(b'ipz')
b'mississ'>>> b'Monty Python'.rstrip(b' Python')
b'M'
>>> b'Monty Python'.removesuffix(b' Python')
b'Monty'>>> b'1,2,3'.split(b',')
[b'1', b'2', b'3']
>>> b'1,2,3'.split(b',', maxsplit=1)
[b'1', b'2,3']
>>> b'1,2,,3,'.split(b',')
[b'1', b'2', b'', b'3', b'']>>> b'1 2 3'.split()
[b'1', b'2', b'3']
>>> b'1 2 3'.split(maxsplit=1)
[b'1', b'2 3']
>>> b' 1 2 3 '.split()
[b'1', b'2', b'3']>>> b' spacious '.strip()
b'spacious'
>>> b'www.example.com'.strip(b'cmowz.')
b'example'>>> b'01\t012\t0123\t01234'.expandtabs()
b'01 012 0123 01234'
>>> b'01\t012\t0123\t01234'.expandtabs(4)
b'01 012 0123 01234'>>> b'ABCabc1'.isalnum()
True
>>> b'ABC abc1'.isalnum()
False>>> b'ABCabc'.isalpha()
True
>>> b'ABCabc1'.isalpha()
False>>> b'1234'.isdigit()
True
>>> b'1.23'.isdigit()
False>>> b'hello world'.islower()
True
>>> b'Hello world'.islower()
False>>> b'Hello World'.istitle()
True
>>> b'Hello world'.istitle()
False>>> b'HELLO WORLD'.isupper()
True
>>> b'Hello world'.isupper()
False>>> b'Hello World'.lower()
b'hello world'>>> b'ab c\n\nde fg\rkl\r\n'.splitlines()
[b'ab c', b'', b'de fg', b'kl']
>>> b'ab c\n\nde fg\rkl\r\n'.splitlines(keepends=True)
[b'ab c\n', b'\n', b'de fg\r', b'kl\r\n']>>> b"".split(b'\n'), b"Two lines\n".split(b'\n')
([b''], [b'Two lines', b''])
>>> b"".splitlines(), b"One line\n".splitlines()
([], [b'One line'])>>> b'Hello World'.swapcase()
b'hELLO wORLD'>>> b'Hello world'.title()
b'Hello World'>>> b"they're bill's friends from the UK".title()
b"They'Re Bill'S Friends From The Uk">>> import re
>>> def titlecase(s):
... return re.sub(rb"[A-Za-z]+('[A-Za-z]+)?",
... lambda mo: mo.group(0)[0:1].upper() +
... mo.group(0)[1:].lower(),
... s)
...
>>> titlecase(b"they're bill's friends.")
b"They're Bill's Friends.">>> b'Hello World'.upper()
b'HELLO WORLD'>>> b"42".zfill(5)
b'00042'
>>> b"-42".zfill(5)
b'-0042'>>> print(b'%(language)s has %(number)03d quote types.' %
... {b'language': b"Python", b"number": 2})
b'Python has 002 quote types.'>>> v = memoryview(b'abcefg')
>>> v[1]
98
>>> v[-1]
103
>>> v[1:4]
<memory at 0x7f3ddc9f4350>
>>> bytes(v[1:4])
b'bce'>>> import array
>>> a = array.array('l', [-11111111, 22222222, -33333333, 44444444])
>>> m = memoryview(a)
>>> m[0]
-11111111
>>> m[-1]
44444444
>>> m[::2].tolist()
[-11111111, -33333333]>>> data = bytearray(b'abcefg')
>>> v = memoryview(data)
>>> v.readonly
False
>>> v[0] = ord(b'z')
>>> data
bytearray(b'zbcefg')
>>> v[1:4] = b'123'
>>> data
bytearray(b'z123fg')
>>> v[2:3] = b'spam'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: memoryview assignment: lvalue and rvalue have different structures
>>> v[2:6] = b'spam'
>>> data
bytearray(b'z1spam')>>> v = memoryview(b'abcefg')
>>> hash(v) == hash(b'abcefg')
True
>>> hash(v[2:4]) == hash(b'ce')
True
>>> hash(v[::-2]) == hash(b'abcefg'[::-2])
True>>> import array
>>> a = array.array('I', [1, 2, 3, 4, 5])
>>> b = array.array('d', [1.0, 2.0, 3.0, 4.0, 5.0])
>>> c = array.array('b', [5, 3, 1])
>>> x = memoryview(a)
>>> y = memoryview(b)
>>> x == a == y == b
True
>>> x.tolist() == a.tolist() == y.tolist() == b.tolist()
True
>>> z = y[::-2]
>>> z == c
True
>>> z.tolist() == c.tolist()
True>>> from ctypes import BigEndianStructure, c_long
>>> class BEPoint(BigEndianStructure):
... _fields_ = [("x", c_long), ("y", c_long)]
...
>>> point = BEPoint(100, 200)
>>> a = memoryview(point)
>>> b = memoryview(point)
>>> a == point
False
>>> a == b
False>>> m = memoryview(b"abc")
>>> m.tobytes()
b'abc'
>>> bytes(m)
b'abc'>>> m = memoryview(b"abc")
>>> m.hex()
'616263'>>> memoryview(b'abc').tolist()
[97, 98, 99]
>>> import array
>>> a = array.array('d', [1.1, 2.2, 3.3])
>>> m = memoryview(a)
>>> m.tolist()
[1.1, 2.2, 3.3]>>> m = memoryview(bytearray(b'abc'))
>>> mm = m.toreadonly()
>>> mm.tolist()
[89, 98, 99]
>>> mm[0] = 42
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot modify read-only memory
>>> m[0] = 43
>>> mm.tolist()
[43, 98, 99]>>> m = memoryview(b'abc')
>>> m.release()
>>> m[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operation forbidden on released memoryview object>>> with memoryview(b'abc') as m:
... m[0]
...
97
>>> m[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: operation forbidden on released memoryview object>>> import array
>>> a = array.array('l', [1,2,3])
>>> x = memoryview(a)
>>> x.format
'l'
>>> x.itemsize
8
>>> len(x)
3
>>> x.nbytes
24
>>> y = x.cast('B')
>>> y.format
'B'
>>> y.itemsize
1
>>> len(y)
24
>>> y.nbytes
24>>> b = bytearray(b'zyz')
>>> x = memoryview(b)
>>> x[0] = b'a'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: memoryview: invalid value for format "B"
>>> y = x.cast('c')
>>> y[0] = b'a'
>>> b
bytearray(b'ayz')>>> import struct
>>> buf = struct.pack("i"*12, *list(range(12)))
>>> x = memoryview(buf)
>>> y = x.cast('i', shape=[2,2,3])
>>> y.tolist()
[[[0, 1, 2], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
>>> y.format
'i'
>>> y.itemsize
4
>>> len(y)
2
>>> y.nbytes
48
>>> z = y.cast('b')
>>> z.format
'b'
>>> z.itemsize
1
>>> len(z)
48
>>> z.nbytes
48>>> buf = struct.pack("L"*6, *list(range(6)))
>>> x = memoryview(buf)
>>> y = x.cast('L', shape=[2,3])
>>> len(y)
2
>>> y.nbytes
48
>>> y.tolist()
[[0, 1, 2], [3, 4, 5]]>>> b = bytearray(b'xyz')
>>> m = memoryview(b)
>>> m.obj is b
True>>> import array
>>> a = array.array('i', [1,2,3,4,5])
>>> m = memoryview(a)
>>> len(m)
5
>>> m.nbytes
20
>>> y = m[::2]
>>> len(y)
3
>>> y.nbytes
12
>>> len(y.tobytes())
12>>> import struct
>>> buf = struct.pack("d"*12, *[1.5*x for x in range(12)])
>>> x = memoryview(buf)
>>> y = x.cast('d', shape=[3,4])
>>> y.tolist()
[[0.0, 1.5, 3.0, 4.5], [6.0, 7.5, 9.0, 10.5], [12.0, 13.5, 15.0, 16.5]]
>>> len(y)
3
>>> y.nbytes
96>>> import array, struct
>>> m = memoryview(array.array('H', [32000, 32001, 32002]))
>>> m.itemsize
2
>>> m[0]
32000
>>> struct.calcsize('H') == m.itemsize
True>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> f = dict({'one': 1, 'three': 3}, two=2)
>>> a == b == c == d == e == f
True>>> class Counter(dict):
... def __missing__(self, key):
... return 0
>>> c = Counter()
>>> c['red']
0
>>> c['red'] += 1
>>> c['red']
1>>> d = {'a': 1}
>>> d.values() == d.values()
False>>> d = {"one": 1, "two": 2, "three": 3, "four": 4}
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> list(d)
['one', 'two', 'three', 'four']
>>> list(d.values())
[1, 2, 3, 4]
>>> d["one"] = 42
>>> d
{'one': 42, 'two': 2, 'three': 3, 'four': 4}
>>> del d["two"]
>>> d["two"] = None
>>> d
{'one': 42, 'three': 3, 'four': 4, 'two': None}>>> d = {"one": 1, "two": 2, "three": 3, "four": 4}
>>> d
{'one': 1, 'two': 2, 'three': 3, 'four': 4}
>>> list(reversed(d))
['four', 'three', 'two', 'one']
>>> list(reversed(d.values()))
[4, 3, 2, 1]
>>> list(reversed(d.items()))
[('four', 4), ('three', 3), ('two', 2), ('one', 1)]>>> dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500}
>>> keys = dishes.keys()
>>> values = dishes.values()
>>> # iteration
>>> n = 0
>>> for val in values:
... n += val
>>> print(n)
504
>>> # keys and values are iterated over in the same order (insertion order)
>>> list(keys)
['eggs', 'sausage', 'bacon', 'spam']
>>> list(values)
[2, 1, 1, 500]
>>> # view objects are dynamic and reflect dict changes
>>> del dishes['eggs']
>>> del dishes['sausage']
>>> list(keys)
['bacon', 'spam']
>>> # set operations
>>> keys & {'eggs', 'bacon', 'salad'}
{'bacon'}
>>> keys ^ {'sausage', 'juice'}
{'juice', 'sausage', 'bacon', 'spam'}def average(values: list[float]) -> float:
return sum(values) / len(values)def send_post_request(url: str, body: dict[str, int]) -> None:
...>>> isinstance([1, 2], list[str])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: isinstance() argument 2 cannot be a parameterized generic>>> t = list[str]
>>> t([1, 2, 3])
[1, 2, 3]>>> t = list[str]
>>> type(t)
<class 'types.GenericAlias'>
>>> l = t()
>>> type(l)
<class 'list'>>>> repr(list[int])
'list[int]'
>>> str(list[int])
'list[int]'>>> dict[str][str]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: There are no type variables left in dict[str]>>> from typing import TypeVar
>>> Y = TypeVar('Y')
>>> dict[str, Y][int]
dict[str, int]>>> list[int].__origin__
<class 'list'>>>> dict[str, list[int]].__args__
(<class 'str'>, list[int])>>> from typing import TypeVar
>>> T = TypeVar('T')
>>> list[T].__parameters__
(~T,)>>> class C:
... def method(self):
... pass
...
>>> c = C()
>>> c.method.whoami = 'my name is method' # can't set on the method
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'method' object has no attribute 'whoami'
>>> c.method.__func__.whoami = 'my name is method'
>>> c.method.whoami
'my name is method'>>> int.__subclasses__()
[<class 'bool'>]>>> lists = [[]] * 3
>>> lists
[[], [], []]
>>> lists[0].append(3)
>>> lists
[[3], [3], [3]]>>> lists = [[] for i in range(3)]
>>> lists[0].append(3)
>>> lists[1].append(5)
>>> lists[2].append(7)
>>> lists
[[3], [5], [7]]asabeneh@Asabeneh:~$ python
Python 3.9.6 (default, Jun 28 2021, 15:26:21)
[Clang 11.0.0 (clang-1100.0.33.8)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> num = 10
>>> type(num)
<class 'int'>
>>> string = 'string'
>>> type(string)
<class 'str'>
>>> boolean = True
>>> type(boolean)
<class 'bool'>
>>> lst = []
>>> type(lst)
<class 'list'>
>>> tpl = ()
>>> type(tpl)
<class 'tuple'>
>>> set1 = set()
>>> type(set1)
<class 'set'>
>>> dct = {}
>>> type(dct)
<class 'dict'># syntax
class ClassName:
code goes hereclass Person:
pass
print(Person)<__main__.Person object at 0x10804e510>p = Person()
print(p)class Person:
def __init__ (self, name):
# self allows to attach parameter to the class
self.name =name
p = Person('Asabeneh')
print(p.name)
print(p)# output
Asabeneh
<__main__.Person object at 0x2abf46907e80>class Person:
def __init__(self, firstname, lastname, age, country, city):
self.firstname = firstname
self.lastname = lastname
self.age = age
self.country = country
self.city = city
p = Person('Asabeneh', 'Yetayeh', 250, 'Finland', 'Helsinki')
print(p.firstname)
print(p.lastname)
print(p.age)
print(p.country)
print(p.city)# output
Asabeneh
Yetayeh
250
Finland
Helsinkiclass Person:
def __init__(self, firstname, lastname, age, country, city):
self.firstname = firstname
self.lastname = lastname
self.age = age
self.country = country
self.city = city
def person_info(self):
return f'{self.firstname} {self.lastname} is {self.age} years old. He lives in {self.city}, {self.country}'
p = Person('Asabeneh', 'Yetayeh', 250, 'Finland', 'Helsinki')
print(p.person_info())# output
Asabeneh Yetayeh is 250 years old. He lives in Helsinki, Finlandclass Person:
def __init__(self, firstname='Asabeneh', lastname='Yetayeh', age=250, country='Finland', city='Helsinki'):
self.firstname = firstname
self.lastname = lastname
self.age = age
self.country = country
self.city = city
def person_info(self):
return f'{self.firstname} {self.lastname} is {self.age} years old. He lives in {self.city}, {self.country}.'
p1 = Person()
print(p1.person_info())
p2 = Person('John', 'Doe', 30, 'Nomanland', 'Noman city')
print(p2.person_info())# output
Asabeneh Yetayeh is 250 years old. He lives in Helsinki, Finland.
John Doe is 30 years old. He lives in Noman city, Nomanland.class Person:
def __init__(self, firstname='Asabeneh', lastname='Yetayeh', age=250, country='Finland', city='Helsinki'):
self.firstname = firstname
self.lastname = lastname
self.age = age
self.country = country
self.city = city
self.skills = []
def person_info(self):
return f'{self.firstname} {self.lastname} is {self.age} years old. He lives in {self.city}, {self.country}.'
def add_skill(self, skill):
self.skills.append(skill)
p1 = Person()
print(p1.person_info())
p1.add_skill('HTML')
p1.add_skill('CSS')
p1.add_skill('JavaScript')
p2 = Person('John', 'Doe', 30, 'Nomanland', 'Noman city')
print(p2.person_info())
print(p1.skills)
print(p2.skills)# output
Asabeneh Yetayeh is 250 years old. He lives in Helsinki, Finland.
John Doe is 30 years old. He lives in Noman city, Nomanland.
['HTML', 'CSS', 'JavaScript']
[]class Student(Person):
pass
s1 = Student('Eyob', 'Yetayeh', 30, 'Finland', 'Helsinki')
s2 = Student('Lidiya', 'Teklemariam', 28, 'Finland', 'Espoo')
print(s1.person_info())
s1.add_skill('JavaScript')
s1.add_skill('React')
s1.add_skill('Python')
print(s1.skills)
print(s2.person_info())
s2.add_skill('Organizing')
s2.add_skill('Marketing')
s2.add_skill('Digital Marketing')
print(s2.skills)output
Eyob Yetayeh is 30 years old. He lives in Helsinki, Finland.
['JavaScript', 'React', 'Python']
Lidiya Teklemariam is 28 years old. He lives in Espoo, Finland.
['Organizing', 'Marketing', 'Digital Marketing']class Student(Person):
def __init__ (self, firstname='Asabeneh', lastname='Yetayeh',age=250, country='Finland', city='Helsinki', gender='male'):
self.gender = gender
super().__init__(firstname, lastname,age, country, city)
def person_info(self):
gender = 'He' if self.gender =='male' else 'She'
return f'{self.firstname} {self.lastname} is {self.age} years old. {gender} lives in {self.city}, {self.country}.'
s1 = Student('Eyob', 'Yetayeh', 30, 'Finland', 'Helsinki','male')
s2 = Student('Lidiya', 'Teklemariam', 28, 'Finland', 'Espoo', 'female')
print(s1.person_info())
s1.add_skill('JavaScript')
s1.add_skill('React')
s1.add_skill('Python')
print(s1.skills)
print(s2.person_info())
s2.add_skill('Organizing')
s2.add_skill('Marketing')
s2.add_skill('Digital Marketing')
print(s2.skills)Eyob Yetayeh is 30 years old. He lives in Helsinki, Finland.
['JavaScript', 'React', 'Python']
Lidiya Teklemariam is 28 years old. She lives in Espoo, Finland.
['Organizing', 'Marketing', 'Digital Marketing']ages = [31, 26, 34, 37, 27, 26, 32, 32, 26, 27, 27, 24, 32, 33, 27, 25, 26, 38, 37, 31, 34, 24, 33, 29, 26]
print('Count:', data.count()) # 25
print('Sum: ', data.sum()) # 744
print('Min: ', data.min()) # 24
print('Max: ', data.max()) # 38
print('Range: ', data.range() # 14
print('Mean: ', data.mean()) # 30
print('Median: ', data.median()) # 29
print('Mode: ', data.mode()) # {'mode': 26, 'count': 5}
print('Standard Deviation: ', data.std()) # 4.2
print('Variance: ', data.var()) # 17.5
print('Frequency Distribution: ', data.freq_dist()) # [(20.0, 26), (16.0, 27), (12.0, 32), (8.0, 37), (8.0, 34), (8.0, 33), (8.0, 31), (8.0, 24), (4.0, 38), (4.0, 29), (4.0, 25)]# you output should look like this
print(data.describe())
Count: 25
Sum: 744
Min: 24
Max: 38
Range: 14
Mean: 30
Median: 29
Mode: (26, 5)
Variance: 17.5
Standard Deviation: 4.2
Frequency Distribution: [(20.0, 26), (16.0, 27), (12.0, 32), (8.0, 37), (8.0, 34), (8.0, 33), (8.0, 31), (8.0, 24), (4.0, 38), (4.0, 29), (4.0, 25)]"""
Abstract class is an extension of a basic class. Like a basic class, an
abstract class has methods and state. Unlike a basic class, it inherits
the `ABC` class and has at least one `abstractmethod`. That means we
cannot create an instance directly from its constructor. In this module,
we will create an abstract class and two concrete classes.
For more about abstract classes, click the link below:
https://www.python.org/dev/peps/pep-3119/
"""
from abc import ABC, abstractmethod
class Employee(ABC):
"""Abstract definition of an employee.
Any employee can work and relax. The way that one type of employee
can work and relax is different from another type of employee.
"""
def __init__(self, name, title):
self.name = name
self.title = title
def __str__(self):
return self.name
@abstractmethod
def do_work(self):
"""Do something for work."""
raise NotImplementedError
@abstractmethod
def do_relax(self):
"""Do something to relax."""
raise NotImplementedError
class Engineer(Employee):
"""Concrete definition of an engineer.
The Engineer class is concrete because it implements every
`abstractmethod` that was not implemented above.
Notice that we leverage the parent's constructor when creating
this object. We also define `do_refactor` for an engineer, which
is something that a manager prefers not to do.
"""
def __init__(self, name, title, skill):
super().__init__(name, title)
self.skill = skill
def do_work(self):
return f"{self} is coding in {self.skill}"
def do_relax(self):
return f"{self} is watching YouTube"
def do_refactor(self):
"""Do the hard work of refactoring code, unlike managers."""
return f"{self} is refactoring code"
class Manager(Employee):
"""Concrete definition of a manager.
The Manager class is concrete for the same reasons as the Engineer
class is concrete. Notice that a manager has direct reports and
has the responsibility of hiring people on the team, unlike an
engineer.
"""
def __init__(self, name, title, direct_reports):
super().__init__(name, title)
self.direct_reports = direct_reports
def do_work(self):
return f"{self} is meeting up with {len(self.direct_reports)} reports"
def do_relax(self):
return f"{self} is taking a trip to the Bahamas"
def do_hire(self):
"""Do the hard work of hiring employees, unlike engineers."""
return f"{self} is hiring employees"
def main():
# Declare two engineers
engineer_john = Engineer("John Doe", "Software Engineer", "Android")
engineer_jane = Engineer("Jane Doe", "Software Engineer", "iOS")
engineers = [engineer_john, engineer_jane]
# These engineers are employees but not managers
assert all(isinstance(engineer, Employee) for engineer in engineers)
assert all(not isinstance(engineer, Manager) for engineer in engineers)
# Engineers can work, relax and refactor
assert engineer_john.do_work() == "John Doe is coding in Android"
assert engineer_john.do_relax() == "John Doe is watching YouTube"
assert engineer_john.do_refactor() == "John Doe is refactoring code"
# Declare manager with engineers as direct reports
manager_max = Manager("Max Doe", "Engineering Manager", engineers)
# Managers are employees but not engineers
assert isinstance(manager_max, Employee)
assert not isinstance(manager_max, Engineer)
# Managers can work, relax and hire
assert manager_max.do_work() == "Max Doe is meeting up with 2 reports"
assert manager_max.do_relax() == "Max Doe is taking a trip to the Bahamas"
assert manager_max.do_hire() == "Max Doe is hiring employees"
if __name__ == "__main__":
main()
"""
A class is made up of methods and state. This allows code and data to be
combined as one logical entity. This module defines a basic car class,
creates a car instance and uses it for demonstration purposes.
"""
from inspect import isfunction, ismethod, signature
class Car:
"""Basic definition of a car.
We begin with a simple mental model of what a car is. That way, we
can start exploring the core concepts that are associated with a
class definition.
"""
def __init__(self, make, model, year, miles):
"""Constructor logic."""
self.make = make
self.model = model
self.year = year
self.miles = miles
def __repr__(self):
"""Formal representation for developers."""
return f"<Car make={self.make} model={self.model} year={self.year}>"
def __str__(self):
"""Informal representation for users."""
return f"{self.make} {self.model} ({self.year})"
def drive(self, rate_in_mph):
"""Drive car at a certain rate in MPH."""
return f"{self} is driving at {rate_in_mph} MPH"
def main():
# Create a car with the provided class constructor
car = Car("Bumble", "Bee", 2000, 200000.0)
# Formal representation is good for debugging issues
assert repr(car) == "<Car make=Bumble model=Bee year=2000>"
# Informal representation is good for user output
assert str(car) == "Bumble Bee (2000)"
# Call a method on the class constructor
assert car.drive(75) == "Bumble Bee (2000) is driving at 75 MPH"
# As a reminder: everything in Python is an object! And that applies
# to classes in the most interesting way - because they're not only
# subclasses of object - they are also instances of object. This
# means that we can modify the `Car` class at runtime, just like any
# other piece of data we define in Python
assert issubclass(Car, object) and isinstance(Car, object)
# To emphasize the idea that everything is an object, let's look at
# the `drive` method in more detail
driving = getattr(car, "drive")
# The variable method is the same as the instance method
assert driving == car.drive
# The variable method is bound to the instance
assert driving.__self__ == car
# That is why `driving` is considered a method and not a function
assert ismethod(driving) and not isfunction(driving)
# And there is only one parameter for `driving` because `__self__`
# binding is implicit
driving_params = signature(driving).parameters
assert len(driving_params) == 1
assert "rate_in_mph" in driving_params
if __name__ == "__main__":
main()
class Point:
passclass Point:
"Point class for storing mathematical points.">>> type(Point)
<class 'type'>
>>> p = Point()
>>> type(p)
<class '__main__.Point'>>>> p.x = 3
>>> p.y = 4>>> print(p.y)
4
>>> x = p.x
>>> print(x)
3print('({0}, {1})'.format(p.x, p.y))
distance_squared = p.x * p.x + p.y * p.y>>> p2 = Point()
>>> p2.x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Point' object has no attribute 'x'
>>>class Point:
def __init__(self, x, y):
self.x = x
self.y = yclass Point:
def __init__(self, x, y):
self.x = x
self.y = y
def distance_from_origin(self):
return ((self.x ** 2) + (self.y ** 2)) ** 0.5>>> p = Point(3, 4)
>>> p.x
3
>>> p.y
4
>>> p.distance_from_origin()
5.0
>>> q = Point(5, 12)
>>> q.x
5
>>> q.y
12
>>> q.distance_from_origin()
13.0
>>> r = Point(0, 0)
>>> r.x
0
>>> r.y
0
>>> r.distance_from_origin()
0.0def print_point(p):
print('({0}, {1})'.format(p.x, p.y))class Point:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def distance_from_origin(self):
return ((self.x ** 2) + (self.y ** 2)) ** 0.5
def print_point(self):
print('({0}, {1})'.format(self.x, self.y))>>> p = Point(3, 4)
>>> p.print_point()
(3, 4)class Time:
def __init__(self, hours, minutes, seconds):
self.hours = hours
self.minutes = minutes
self.seconds = seconds>>> current_time = Time(9, 14, 30)
>>> current_time.hours
9
>>> current_time.minutes
14
>>> current_time.seconds
30class Time:
# previous method definitions here...
def print_time(self):
s = "{0}:{1:02d}:{2:02d}"
print(s.format(self.hours, self.minutes, self.seconds)>>> t1 = Time(9, 14, 30)
>>> t1.print_time()
9:14:30
>>> t2 = Time(7, 4, 0)
>>> t2.print_time()
7:04:00def find(str, ch):
index = 0
while index < len(str):
if str[index] == ch:
return index
index = index + 1
return -1def find(str, ch, start=0):
index = start
while index < len(str):
if str[index] == ch:
return index
index = index + 1
return -1>>> find("apple", "p")
1>>> find("apple", "p", 2)
2
>>> find("apple", "p", 3)
-1class Time:
def __init__(self, hours=0, minutes=0, seconds=0):
self.hours = hours
self.minutes = minutes
self.seconds = seconds>>> current_time = Time(9, 14, 30)>>> current_time = Time()
>>> current_time.print_time()
0:00:00>>> current_time = Time(9)
>>> current_time.print_time()
9:00:00>>> current_time = Time (9, 14)
>>> current_time.print_time()
9:14:00>>> current_time = Time(seconds = 30, hours = 9)
>>> current_time.print_time()
9:00:30class Time:
# previous method definitions here...
def increment(self, seconds):
self.seconds = seconds + self.seconds
while self.seconds >= 60:
self.seconds = self.seconds - 60
self.minutes = self.minutes + 1
while self.minutes >= 60:
self.minutes = self.minutes - 60
self.hours = self.hours + 1>>> current_time = Time(9, 14, 30)
>>> current_time.increment(125)
>>> current_time.print_time()
9:16:35class Time:
# previous method definitions here...
def after(self, other):
if self.hours > other.hours:
return True
if self.hours < other.hours:
return False
if self.minutes > other.minutes:
return True
if self.minutes < other.minutes:
return False
if self.seconds > other.seconds:
return True
return Falseif time1.after(time2):
print("It's later than you think.")def add_time(t1, t2):
sum = Time()
sum.hours = t1.hours + t2.hours
sum.minutes = t1.minutes + t2.minutes
sum.seconds = t1.seconds + t2.seconds
return sum>>> current_time = Time(9, 14, 30)
>>> bread_time = Time(3, 35, 0)
>>> done_time = add_time(current_time, bread_time)
>>> print_time(done_time)
12:49:30def add_time(t1, t2):
sum = Time()
sum.hours = t1.hours + t2.hours
sum.minutes = t1.minutes + t2.minutes
sum.seconds = t1.seconds + t2.seconds
if sum.seconds >= 60:
sum.seconds = sum.seconds - 60
sum.minutes = sum.minutes + 1
if sum.minutes >= 60:
sum.minutes = sum.minutes - 60
sum.hours = sum.hours + 1
return sumdef increment(time, seconds):
time.seconds = time.seconds + seconds
if time.seconds >= 60:
time.seconds = time.seconds - 60
time.minutes = time.minutes + 1
if time.minutes >= 60:
time.minutes = time.minutes - 60
time.hours = time.hours + 1def increment(time, seconds):
time.seconds = time.seconds + seconds
while time.seconds >= 60:
time.seconds = time.seconds - 60
time.minutes = time.minutes + 1
while time.minutes >= 60:
time.minutes = time.minutes - 60
time.hours = time.hours + 1def convert_to_seconds(time):
minutes = time.hours * 60 + time.minutes
seconds = minutes * 60 + time.seconds
return secondsdef make_time(seconds):
time = Time()
time.hours = seconds // 3600
seconds = seconds - time.hours * 3600
time.minutes = seconds // 60
seconds = seconds - time.minutes * 60
time.seconds = seconds
return timedef add_time(t1, t2):
seconds = convert_to_seconds(t1) + convert_to_seconds(t2)
return make_time(seconds)class Point:
def __init__(self, x=0, y=0):
self.x = x
self.y = y
def __str__(self):
return '({0}, {1})'.format(self.x, self.y)>>> p = Point(3, 4)
>>> str(p)
'(3, 4)'>>> p = Point(3, 4)
>>> print(p)
(3, 4)class Point:
# previously defined methods here...
def __add__(self, other):
return Point(self.x + other.x, self.y + other.y)>>> p1 = Point(3, 4)
>>> p2 = Point(5, 7)
>>> p3 = p1 + p2
>>> print(p3)
(8, 11)def __mul__(self, other):
return self.x * other.x + self.y * other.ydef __rmul__(self, other):
return Point(other * self.x, other * self.y)>>> p1 = Point(3, 4)
>>> p2 = Point(5, 7)
>>> print(p1 * p2)
43
>>> print(2 * p2)
(10, 14)>>> print(p2 * 2)
AttributeError: 'int' object has no attribute 'x'def multadd(x, y, z):
return x * y + z>>> multadd(3, 2, 1)
7>>> p1 = Point(3, 4)
>>> p2 = Point(5, 7)
>>> print(multadd(2, p1, p2))
(11, 15)
>>> print(multadd(p1, p2, 1))
44def front_and_back(front):
import copy
back = copy.copy(front)
back.reverse()
print(str(front) + str(back))>>> myList = [1, 2, 3, 4]
>>> front_and_back(myList)
[1, 2, 3, 4][4, 3, 2, 1]def reverse(self):
self.x , self.y = self.y, self.x>>> p = Point(3, 4)
>>> front_and_back(p)
(3, 4)(4, 3)










def initials(phrase):
words = phrase.split()
result = ""
for word in words:
result += word[0].upper()
return result
print(initials("Universal Serial Bus")) # Should be: USB
print(initials("local area network")) # Should be: LAN
print(initials("Operating system")) # Should be: OS
@bgoonz
"""
This module shows one-liner comprehensions where we make lists, tuples,
sets and dictionaries by looping through iterators.
"""
def main():
# One interesting fact about data structures is that we can build
# them with comprehensions. Let's explain how the first one works:
# we just want to create zeros so our expression is set to `0`
# since no computing is required; because `0` is a constant value,
# we can set the item that we compute with to `_`; and we want to
# create five zeros so we set the iterator as `range(5)`
assert [0 for _ in range(5)] == [0] * 5 == [0, 0, 0, 0, 0]
# For the next comprehension operations, let's see what we can do
# with a list of 3-5 letter words
words = ["cat", "mice", "horse", "bat"]
# Tuple comprehension can find the length for each word
tuple_comp = tuple(len(word) for word in words)
assert tuple_comp == (3, 4, 5, 3)
# Set comprehension can find the unique word lengths
set_comp = {len(word) for word in words}
assert len(set_comp) < len(words)
assert set_comp == {3, 4, 5}
# Dictionary comprehension can map each word to its length
dict_comp = {word: len(word) for word in words}
assert len(dict_comp) == len(words)
assert dict_comp == {"cat": 3, "mice": 4, "horse": 5, "bat": 3}
if __name__ == "__main__":
main()
my_list = [1, 2, 3, 4]
my_list.reverse()
print(my_list) # Output: [4, 3, 2, 1]
new_list = my_list.reverse()
print(new_list) # Output: Nonelist_1 = [1, 2, 3, 4]
list_2 = list_1.copy()
list_1.reverse()
print('Reversed list: ', list_1)
print('Saved original list: ', list_2)Reversed list: [4, 3, 2, 1]
Saved original list: [1, 2, 3, 4]my_list = [1, 2, 3, 4, 5, 6]
# list[start:end:step]
segment_1 = my_list[1:5:1]
segment_2 = my_list[1:5:2]
print(segment_1)
print(segment_2)[2, 3, 4, 5]
[2, 4]original_list = [1, 2, 3, 4, 5, 6]
reversed_list = original_list[::-1]
print('Original list: ', original_list)
print('Reversed list: ', reversed_list)Original list: [1, 2, 3, 4, 5, 6]
Reversed list: [6, 5, 4, 3, 2, 1]original_list = [1, 2, 3, 4, 5, 6]
slice_obj = slice(None, None, -1)
print('slice_obj type:', type(slice_obj))
print('Reversed list:', original_list[slice_obj])slice_obj type: <class 'slice'>
Reversed list: [6, 5, 4, 3, 2, 1]original_list = [1, 2, 3, 4]
reversed_list = []
for i in range(len(original_list)):
reversed_list.append(original_list.pop())
print(reversed_list) # Output: [4, 3, 2, 1]original_list = [1, 2, 3, 4]
reversed_list = []
for i in range(len(original_list)-1, -1, -1):
reversed_list.append(original_list[i])
print(reversed_list) # Output: [4, 3, 2, 1]original_list = [1, 2, 3, 4]
new_list = []
for i in reversed(original_list):
new_list.append(i)
print(new_list) # Output: [4, 3, 2, 1]
print(original_list) # Output: [1, 2, 3, 4] --> Original hasn't changed[]0# -*- coding: utf-8 -*-
"""Copy of Linked Lists.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/gist/bgoonz/73035b719d10a753a44089b41eacf6ca/copy-of-linked-lists.ipynb
# Linked Lists
- Non Contiguous abstract Data Structure
- Value (can be any value for our use we will just use numbers)
- Next (A pointer or reference to the next node in the list)
```
L1 = Node(34)
L1.next = Node(45)
L1.next.next = Node(90)
# while the current node is not none
# do something with the data
# traverse to next node
L1 = [34]-> [45]-> [90] -> None
Node(45)
Node(90)
```
"""
class LinkedListNode:
"""
Simple Singly Linked List Node Class
value -> int
next -> LinkedListNode
"""
def __init__(self, value):
self.value = value
self.next = None
def add_node(self, value):
# set current as a ref to self
current = self
# thile there is still more nodes
while current.next is not None:
# traverse to the next node
current = current.next
# create a new node and set the ref from current.next to the new node
current.next = LinkedListNode(value)
def insert_node(self, value, target):
# create a new node with the value provided
new_node = LinkedListNode(value)
# set a ref to the current node
current = self
# while the current nodes value is not the target
while current.value != target:
# traverse to the next node
current = current.next
# set the new nodes next pointer to point toward the current nodes next pointer
new_node.next = current.next
# set the current nodes next to point to the new node
current.next = new_node
ll_storage = []
L1 = LinkedListNode(34)
L1.next = LinkedListNode(45)
L1.next.next = LinkedListNode(90)
def print_ll(linked_list_node):
current = linked_list_node
while current is not None:
print(current.value)
current = current.next
def add_to_ll_storage(linked_list_node):
current = linked_list_node
while current is not None:
ll_storage.append(current)
current = current.next
L1.add_node(12)
print_ll(L1)
L1.add_node(24)
print()
print_ll(L1)
print()
L1.add_node(102)
print_ll(L1)
L1.insert_node(123, 90)
print()
print_ll(L1)
L1.insert_node(678, 34)
print()
print_ll(L1)
L1.insert_node(999, 102)
print()
print_ll(L1)
"""# CODE 9571"""
class LinkedListNode:
"""
Simple Doubly Linked List Node Class
value -> int
next -> LinkedListNode
prev -> LinkedListNode
"""
def __init__(self, value):
self.value = value
self.next = None
self.prev = None
"""
Given a reference to the head node of a singly-linked list, write a function
that reverses the linked list in place. The function should return the new head
of the reversed list.
In order to do this in O(1) space (in-place), you cannot make a new list, you
need to use the existing nodes.
In order to do this in O(n) time, you should only have to traverse the list
once.
*Note: If you get stuck, try drawing a picture of a small linked list and
running your function by hand. Does it actually work? Also, don't forget to
consider edge cases (like a list with only 1 or 0 elements).*
cn p
None [1] -> [2] ->[3] -> None
- setup a current variable pointing to the head of the list
- set up a prev variable pointing to None
- set up a next variable pointing to None
- while the current ref is not none
- set next to the current.next
- set the current.next to prev
- set prev to current
- set current to next
- return prev
"""
class LinkedListNode():
def __init__(self, value):
self.value = value
self.next = None
def reverse(head_of_list):
current = head_of_list
prev = None
next = None
while current:
next = current.next
current.next = prev
prev = current
current = next
return prev
class HashTableEntry:
"""
Linked List hash table key/value pair
"""
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
# Hash table can't have fewer than this many slots
MIN_CAPACITY = 8
[
0["Lou", 41] -> ["Bob", 41]
1["Steve", 41] -> None,
2["Jen", 41] -> None,
3["Dave", 41] -> None,
4None,
5["Hector", 34] -> None,
6["Lisa", 41] -> None,
7None,
8None,
9None
]
class HashTable:
"""
A hash table that with `capacity` buckets
that accepts string keys
Implement this.
"""
def __init__(self, capacity):
self.capacity = capacity # Number of buckets in the hash table
self.storage = [None] * capacity
self.item_count = 0
def get_num_slots(self):
"""
Return the length of the list you're using to hold the hash
table data. (Not the number of items stored in the hash table,
but the number of slots in the main list.)
One of the tests relies on this.
Implement this.
"""
# Your code here
def get_load_factor(self):
"""
Return the load factor for this hash table.
Implement this.
"""
return len(self.storage)
def djb2(self, key):
"""
DJB2 hash, 32-bit
Implement this, and/or FNV-1.
"""
str_key = str(key).encode()
hash = FNV_offset_basis_64
for b in str_key:
hash *= FNV_prime_64
hash ^= b
hash &= 0xffffffffffffffff # 64-bit hash
return hash
def hash_index(self, key):
"""
Take an arbitrary key and return a valid integer index
between within the storage capacity of the hash table.
"""
return self.djb2(key) % self.capacity
def put(self, key, value):
"""
Store the value with the given key.
Hash collisions should be handled with Linked List Chaining.
Implement this.
"""
index = self.hash_index(key)
current_entry = self.storage[index]
while current_entry is not None and current_entry.key != key:
current_entry = current_entry.next
if current_entry is not None:
current_entry.value = value
else:
new_entry = HashTableEntry(key, value)
new_entry.next = self.storage[index]
self.storage[index] = new_entry
def delete(self, key):
"""
Remove the value stored with the given key.
Print a warning if the key is not found.
Implement this.
"""
# Your code here
def get(self, key):
"""
Retrieve the value stored with the given key.
Returns None if the key is not found.
Implement this.
"""
# Your code here


# syntax
empty_dict = {}
# Dictionary with data values
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}person = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
print(len(dct)) # 4person = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
print(len(person)) # 7# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
print(dct['key1']) # value1
print(dct['key4']) # value4person = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
print(person['first_name']) # Asabeneh
print(person['country']) # Finland
print(person['skills']) # ['JavaScript', 'React', 'Node', 'MongoDB', 'Python']
print(person['skills'][0]) # JavaScript
print(person['address']['street']) # Space street
print(person['city']) # Errorperson = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
print(person.get('first_name')) # Asabeneh
print(person.get('country')) # Finland
print(person.get('skills')) #['HTML','CSS','JavaScript', 'React', 'Node', 'MongoDB', 'Python']
print(person.get('city')) # None# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
dct['key5'] = 'value5'person = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
person['job_title'] = 'Instructor'
person['skills'].append('HTML')
print(person)# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
dct['key1'] = 'value-one'person = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
person['first_name'] = 'Eyob'
person['age'] = 252# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
print('key2' in dct) # True
print('key5' in dct) # False# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
dct.pop('key1') # removes key1 item
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
dct.popitem() # removes the last item
del dct['key2'] # removes key2 itemperson = {
'first_name':'Asabeneh',
'last_name':'Yetayeh',
'age':250,
'country':'Finland',
'is_marred':True,
'skills':['JavaScript', 'React', 'Node', 'MongoDB', 'Python'],
'address':{
'street':'Space street',
'zipcode':'02210'
}
}
person.pop('first_name') # Removes the firstname item
person.popitem() # Removes the address item
del person['is_married'] # Removes the is_married item# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
print(dct.items()) # dict_items([('key1', 'value1'), ('key2', 'value2'), ('key3', 'value3'), ('key4', 'value4')])# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
print(dct.clear()) # None# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
del dct# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
dct_copy = dct.copy() # {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
keys = dct.keys()
print(keys) # dict_keys(['key1', 'key2', 'key3', 'key4'])# syntax
dct = {'key1':'value1', 'key2':'value2', 'key3':'value3', 'key4':'value4'}
values = dct.values()
print(values) # dict_values(['value1', 'value2', 'value3', 'value4'])import itertools
# Given an array of coins and an array of quantities for each coin with the
# same index, determine how many distinct sums can be made from non-zero
# sets of the coins
# Note: This problem took a little more working-through, with a failed brute-
# force attempt that consisted of finding every combination of coins and
# adding them, which failed when I needed to consider >50k coins
# the overall number of coins was guaranteed to be less than about 1 million,
# so the solution appeared to be a form of divide-and-conquer where each
# possible sum for each coin was put into a set at that coin's index in the
# original coins array, and then the sums were repeatedly combined into an
# aggregate set until every coin possible coin value (given by the coins
# array) had been added into the set of sums
# problem considered "hard," asked by Google
def possibleSums(coins, quantity):
# sum_map = set()
# start with brute force
# total_arr = [coins[i] for i, q in enumerate(quantity) for l in range(q)]
# for i in range(1, len(total_arr)+1):
# combos = itertools.combinations(total_arr, i)
# print(combos)
# for combo in combos:
# sum_map.add(sum(combo))
# return len(sum_map)
# faster?
comb_indices = [i for i in range(len(coins))]
possible_sums = []
for i, c in enumerate(coins):
this_set = set()
for q in range(1, 1 + quantity[i]):
this_set.add(c * q)
possible_sums.append(this_set)
# print(possible_sums)
while len(possible_sums) > 1:
possible_sums[0] = combine_sets(possible_sums[0], possible_sums[1])
possible_sums.pop(1)
return len(possible_sums[0])
def combine_sets(set1, set2):
together_set = set()
for item1 in set1:
for item2 in set2:
together_set.add(item1 + item2)
together_set.add(item1)
for item2 in set2:
together_set.add(item2)
return together_set# need strings[i] = strings[j] for all patterns[i] = patterns[j] to be true -
# give false if strings[i] != strings[j] and patterns[i] = patterns[j] or
# strings[i] = strings[j] and patterns[j] != patterns[j] - this last condition
# threw me for a bit as an edge case! Need to ensure that each string is unique
# to each key, not just that each key corresponds to the given string!
# from a google interview set, apparently
def areFollowingPatterns(strings, patterns):
pattern_to_string = {}
string_to_pattern = {}
for i in range(len(patterns)):
# first, check condition that strings are equal for patterns[i]=patterns[j]
this_pattern = patterns[i]
if patterns[i] in pattern_to_string:
if strings[i] != pattern_to_string[this_pattern]:
return False
else:
pattern_to_string[this_pattern] = strings[i]
# now check condition that patterns are equal for strings[i]=strings[j]
# if there are more keys than values, then there is not 1:1 correspondence
if len(pattern_to_string.keys()) != len(set(pattern_to_string.values())):
return False
return True# gives True if two duplicate numbers in the nums array are within k distance
# (inclusive) of one another, measuring by absolute difference in index
# did relatively well on this one, made a greater-than/less-than flip error on
# the conditional for the true case and needed to rewrite my code to remove
# keys from the dictionary without editing it while looping over it, but
# otherwise went well!
# problem considered medium difficulty, from Palantir
def containsCloseNums(nums, k):
num_dict = {}
# setup keys for each number seen, then list their indices
for i, item in enumerate(nums):
if item in num_dict:
num_dict[item].append(i)
else:
num_dict[item] = [i]
# remove all nums that are not repeated
# first make a set of keys to remove to prevent editing the dictionary size while iterating over it
removals = set()
for key in num_dict.keys():
if len(num_dict[key]) < 2:
removals.add(key)
# now remove each key from the num_dict that has fewer than two values
for key in removals:
num_dict.pop(key)
# now check remaining numbers to see if they fall within the desired range
for key in num_dict.keys():
last_ind = num_dict[key][0]
for next_ind in num_dict[key][1:]:
if next_ind - last_ind <= k:
return True
last_ind = next_ind
return Falseif BOOLEAN EXPRESSION:
STATEMENTSfood = 'spam'
if food == 'spam':
print('Ummmm, my favorite!')
print('I feel like saying it 100 times...')
print(100 * (food + '! '))if food == 'spam':
print('Ummmm, my favorite!')
else:
print("No, I won't have it. I want spam!")if BOOLEAN EXPRESSION:
STATEMENTS_1 # executed if condition evaluates to True
else:
STATEMENTS_2 # executed if condition evaluates to Falseif True: # This is always true
pass # so this is always executed, but it does nothing
else:
passif x < y:
STATEMENTS_A
elif x > y:
STATEMENTS_B
else:
STATEMENTS_Cif choice == 'a':
print("You chose 'a'.")
elif choice == 'b':
print("You chose 'b'.")
elif choice == 'c':
print("You chose 'c'.")
else:
print("Invalid choice.")if x < y:
STATEMENTS_A
else:
if x > y:
STATEMENTS_B
else:
STATEMENTS_Cif 0 < x: # assume x is an int here
if x < 10:
print("x is a positive single digit.")if 0 < x and x < 10:
print("x is a positive single digit.")if 0 < x < 10:
print("x is a positive single digit.")bruce = 5
print(bruce)
bruce = 7
print(bruce)5
7a = 5
b = a # after executing this line, a and b are now equal
a = 3 # after executing this line, a and b are no longer equaln = 5
n = 3 * n + 1>>> w = x + 1
Traceback (most recent call last):
File "<interactive input>", line 1, in
NameError: name 'x' is not defined>>> x = 0
>>> x = x + 1for LOOP_VARIABLE in SEQUENCE:
STATEMENTSfor friend in ['Margot', 'Kathryn', 'Prisila']:
invitation = "Hi " + friend + ". Please come to my party on Saturday!"
print(invitation)>>> for i in range(5):
... print('i is now:', i)
...
i is now 0
i is now 1
i is now 2
i is now 3
i is now 4
>>>for x in range(13): # Generate numbers 0 to 12
print(x, '\t', 2**x)0 1
1 2
2 4
3 8
4 16
5 32
6 64
7 128
8 256
9 512
10 1024
11 2048
12 4096while BOOLEAN_EXPRESSION:
STATEMENTSnumber = 0
prompt = "What is the meaning of life, the universe, and everything? "
while number != "42":
number = input(prompt)name = 'Harrison'
guess = input("So I'm thinking of person's name. Try to guess it: ")
pos = 0
while guess != name and pos < len(name):
print("Nope, that's not it! Hint: letter ", end='')
print(pos + 1, "is", name[pos] + ". ", end='')
guess = input("Guess again: ")
pos = pos + 1
if pos == len(name) and name != guess:
print("Too bad, you couldn't get it. The name was", name + ".")
else:
print("\nGreat, you got it in", pos + 1, "guesses!")name guess pos output
---- ----- --- ------
'Harrison' 'Maribel' 0Nope, that's not it! Hint: letter 1 is 'H'. Guess again:name guess pos output
---- ----- --- ------
'Harrison' 'Maribel' 0 Nope, that's not it! Hint: letter 1 is 'H'. Guess again:
'Harrison' 'Henry' 1 Nope, that's not it! Hint: letter 2 is 'a'. Guess again:name guess pos output
---- ----- --- ------
'Harrison' 'Maribel' 0 Nope, that's not it! Hint: letter 1 is 'H'. Guess again:
'Harrison' 'Henry' 1 Nope, that's not it! Hint: letter 2 is 'a'. Guess again:
'Harrison' 'Hakeem' 2 Nope, that's not it! Hint: letter 3 is 'r'. Guess again:
'Harrison' 'Harold' 3 Nope, that's not it! Hint: letter 4 is 'r'. Guess again:
'Harrison' 'Harry' 4 Nope, that's not it! Hint: letter 5 is 'i'. Guess again:
'Harrison' 'Harrison' 5 Great, you got it in 6 guesses!>>> count = 0
>>> count += 1
>>> count
1
>>> count += 1
>>> count
2>>> n = 2
>>> n += 5
>>> n
7>>> n = 2
>>> n *= 5
>>> n
10
>>> n -= 4
>>> n
6
>>> n //= 2
>>> n
3
>>> n %= 2
>>> n
1import random # Import the random module
number = random.randrange(1, 1000) # Get random number between [1 and 1000)
guesses = 0
guess = int(input("Guess my number between 1 and 1000: "))
while guess != number:
guesses += 1
if guess > number:
print(guess, "is too high.")
elif guess < number:
print(guess, " is too low.")
guess = int(input("Guess again: "))
print("\n\nGreat, you got it in", guesses, "guesses!")for i in [12, 16, 17, 24, 29]:
if i % 2 == 1: # if the number is odd
break # immediately exit the loop
print(i)
print("done")12
16
donefor i in [12, 16, 17, 24, 29, 30]:
if i % 2 == 1: # if the number is odd
continue # don't process it
print(i)
print("done")12
16
24
30
donesentence = input('Please enter a sentence: ')
no_spaces = ''
for letter in sentence:
if letter != ' ':
no_spaces += letter
print("You sentence with spaces removed:")
print(no_spaces)students = [("Alejandro", ["CompSci", "Physics"]),
("Justin", ["Math", "CompSci", "Stats"]),
("Ed", ["CompSci", "Accounting", "Economics"]),
("Margot", ["InfSys", "Accounting", "Economics", "CommLaw"]),
("Peter", ["Sociology", "Economics", "Law", "Stats", "Music"])]# print all students with a count of their courses.
for (name, subjects) in students:
print(name, "takes", len(subjects), "courses")Aljandro takes 2 courses
Justin takes 3 courses
Ed takes 4 courses
Margot takes 4 courses
Peter takes 5 courses# Count how many students are taking CompSci
counter = 0
for (name, subjects) in students:
for s in subjects: # a nested loop!
if s == "CompSci":
counter += 1
print("The number of students taking CompSci is", counter)The number of students taking CompSci is 3>>> numbers = [1, 2, 3, 4]
>>> [x**2 for x in numbers]
[1, 4, 9, 16]
>>> [x**2 for x in numbers if x**2 > 8]
[9, 16]
>>> [(x, x**2, x**3) for x in numbers]
[(1, 1, 1), (2, 4, 8), (3, 9, 27), (4, 16, 64)]
>>> files = ['bin', 'Data', 'Desktop', '.bashrc', '.ssh', '.vimrc']
>>> [name for name in files if name[0] != '.']
['bin', 'Data', 'Desktop']
>>> letters = ['a', 'b', 'c']
>>> [n * letter for n in numbers for letter in letters]
['a', 'b', 'c', 'aa', 'bb', 'cc', 'aaa', 'bbb', 'ccc', 'aaaa', 'bbbb', 'cccc']
>>>[expr for item1 in seq1 for item2 in seq2 ... for itemx in seqx if condition]output_sequence = []
for item1 in seq1:
for item2 in seq2:
...
for itemx in seqx:
if condition:
output_sequence.append(expr)Spades --> 3
Hearts --> 2
Diamonds --> 1
Clubs --> 0Jack --> 11
Queen --> 12
King --> 13class Card:
def __init__(self, suit=0, rank=0):
self.suit = suit
self.rank = rankthree_of_clubs = Card(0, 3)class Card:
SUITS = ('Clubs', 'Diamonds', 'Hearts', 'Spades')
RANKS = ('narf', 'Ace', '2', '3', '4', '5', '6', '7',
'8', '9', '10', 'Jack', 'Queen', 'King']
def __init__(self, suit=0, rank=0):
self.suit = suit
self.rank = rank
def __str__(self):
"""
>>> print(Card(2, 11))
Queen of Hearts
"""
return '{0} of {1}'.format(Card.RANKS[self.rank],
Card.SUITS[self.suit])
if __name__ == '__main__':
import doctest
doctest.testmod()def __cmp__(self, other):
# check the suits
if self.suit > other.suit: return 1
if self.suit < other.suit: return -1
# suits are the same... check ranks
if self.rank > other.rank: return 1
if self.rank < other.rank: return -1
# ranks are the same... it's a tie
return 0class Deck:
def __init__(self):
self.cards = []
for suit in range(4):
for rank in range(1, 14):
self.cards.append(Card(suit, rank))class Deck:
...
def print_deck(self):
for card in self.cards:
print(card)class Deck:
...
def __str__(self):
s = ""
for i in range(len(self.cards)):
s += " " * i + str(self.cards[i]) + "\n"
return s>>> deck = Deck()
>>> print(deck)
Ace of Clubs
2 of Clubs
3 of Clubs
4 of Clubs
5 of Clubs
6 of Clubs
7 of Clubs
8 of Clubs
9 of Clubs
10 of Clubs
Jack of Clubs
Queen of Clubs
King of Clubs
Ace of Diamondsrandom.randrange(0, len(self.cards))class Deck:
...
def shuffle(self):
import random
num_cards = len(self.cards)
for i in range(num_cards):
j = random.randrange(i, num_cards)
self.cards[i], self.cards[j] = self.cards[j], self.cards[i]self.cards[i], self.cards[j] = self.cards[j], self.cards[i]class Deck:
...
def remove(self, card):
if card in self.cards:
self.cards.remove(card)
return True
else:
return Falseclass Deck:
...
def pop(self):
return self.cards.pop()class Deck:
...
def is_empty(self):
return (len(self.cards) == 0)class Hand(Deck):
passclass Hand(Deck):
def __init__(self, name=""):
self.cards = []
self.name = nameclass Hand(Deck):
...
def add(self,card):
self.cards.append(card)class Deck :
...
def deal(self, hands, num_cards=999):
num_hands = len(hands)
for i in range(num_cards):
if self.is_empty(): break # break if out of cards
card = self.pop() # take the top card
hand = hands[i % num_hands] # whose turn is next?
hand.add(card) # add the card to the hand>>> deck = Deck()
>>> deck.shuffle()
>>> hand = Hand("frank")
>>> deck.deal([hand], 5)
>>> print(hand)
Hand frank contains
2 of Spades
3 of Spades
4 of Spades
Ace of Hearts
9 of Clubsclass Hand(Deck)
...
def __str__(self):
s = "Hand " + self.name
if self.is_empty():
s = s + " is empty\n"
else:
s = s + " contains\n"
return s + Deck.__str__(self)class CardGame:
def __init__(self):
self.deck = Deck()
self.deck.shuffle()class OldMaidHand(Hand):
def remove_matches(self):
count = 0
original_cards = self.cards[:]
for card in original_cards:
match = Card(3 - card.suit, card.rank)
if match in self.cards:
self.cards.remove(card)
self.cards.remove(match)
print("Hand {0}: {1} matches {2}".format(self.name, card, match)
count = count + 1
return count>>> game = CardGame()
>>> hand = OldMaidHand("frank")
>>> game.deck.deal([hand], 13)
>>> print(hand)
Hand frank contains
Ace of Spades
2 of Diamonds
7 of Spades
8 of Clubs
6 of Hearts
8 of Spades
7 of Clubs
Queen of Clubs
7 of Diamonds
5 of Clubs
Jack of Diamonds
10 of Diamonds
10 of Hearts
>>> hand.remove_matches()
Hand frank: 7 of Spades matches 7 of Clubs
Hand frank: 8 of Spades matches 8 of Clubs
Hand frank: 10 of Diamonds matches 10 of Hearts
>>> print(hand)
Hand frank contains
Ace of Spades
2 of Diamonds
6 of Hearts
Queen of Clubs
7 of Diamonds
5 of Clubs
Jack of Diamondsclass OldMaidGame(CardGame):
def play(self, names):
# remove Queen of Clubs
self.deck.remove(Card(0,12))
# make a hand for each player
self.hands = []
for name in names:
self.hands.append(OldMaidHand(name))
# deal the cards
self.deck.deal(self.hands)
print("---------- Cards have been dealt")
self.printHands()
# remove initial matches
matches = self.removeAllMatches()
print("---------- Matches discarded, play begins")
self.printHands()
# play until all 50 cards are matched
turn = 0
numHands = len(self.hands)
while matches < 25:
matches = matches + self.playOneTurn(turn)
turn = (turn + 1) % numHands
print("---------- Game is Over")
self.printHands()class OldMaidGame(CardGame):
...
def remove_all_matches(self):
count = 0
for hand in self.hands:
count = count + hand.remove_matches()
return countclass OldMaidGame(CardGame):
...
def play_one_turn(self, i):
if self.hands[i].is_empty():
return 0
neighbor = self.find_neighbor(i)
pickedCard = self.hands[neighbor].popCard()
self.hands[i].add(pickedCard)
print("Hand", self.hands[i].name, "picked", pickedCard)
count = self.hands[i].remove_matches()
self.hands[i].shuffle()
return countclass OldMaidGame(CardGame):
...
def find_neighbor(self, i):
numHands = len(self.hands)
for next in range(1,numHands):
neighbor = (i + next) % numHands
if not self.hands[neighbor].is_empty():
return neighbor>>> import cards
>>> game = cards.OldMaidGame()
>>> game.play(["Allen","Jeff","Chris"])
---------- Cards have been dealt
Hand Allen contains
King of Hearts
Jack of Clubs
Queen of Spades
King of Spades
10 of Diamonds
Hand Jeff contains
Queen of Hearts
Jack of Spades
Jack of Hearts
King of Diamonds
Queen of Diamonds
Hand Chris contains
Jack of Diamonds
King of Clubs
10 of Spades
10 of Hearts
10 of Clubs
Hand Jeff: Queen of Hearts matches Queen of Diamonds
Hand Chris: 10 of Spades matches 10 of Clubs
---------- Matches discarded, play begins
Hand Allen contains
King of Hearts
Jack of Clubs
Queen of Spades
King of Spades
10 of Diamonds
Hand Jeff contains
Jack of Spades
Jack of Hearts
King of Diamonds
Hand Chris contains
Jack of Diamonds
King of Clubs
10 of Hearts
Hand Allen picked King of Diamonds
Hand Allen: King of Hearts matches King of Diamonds
Hand Jeff picked 10 of Hearts
Hand Chris picked Jack of Clubs
Hand Allen picked Jack of Hearts
Hand Jeff picked Jack of Diamonds
Hand Chris picked Queen of Spades
Hand Allen picked Jack of Diamonds
Hand Allen: Jack of Hearts matches Jack of Diamonds
Hand Jeff picked King of Clubs
Hand Chris picked King of Spades
Hand Allen picked 10 of Hearts
Hand Allen: 10 of Diamonds matches 10 of Hearts
Hand Jeff picked Queen of Spades
Hand Chris picked Jack of Spades
Hand Chris: Jack of Clubs matches Jack of Spades
Hand Jeff picked King of Spades
Hand Jeff: King of Clubs matches King of Spades
---------- Game is Over
Hand Allen is empty
Hand Jeff contains
Queen of Spades
Hand Chris is empty
# define main function to print out something
def main():
i = 1
max = 10
while (i < max):
print(i)
i = i + 1
# call function main
main()Code language: Python (python)# This is a single line comment in PythonCode language: Python (python)if (a == True) and (b == False) and \
(c == True):
print("Continuation of statements")Code language: Python (python)False class finally is return
None continue for lambda try
True def from nonlocal while
and del global not with
as elif if or yield
assert else import pass
break except in raiseCode language: Python (python)import keyword
print(keyword.kwlist) Code language: Python (python)s = 'This is a string'
print(s)
s = "Another string using double quotes"
print(s)
s = ''' string can span
multiple line '''
print(s)Code language: Python (python)