
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Objective 01 - Recall the different traversal types for a binary tree and implement a function to complete the traversal for each type
def toHex(dec):
digits = "0123456789ABCDEF"
x = (dec % 16)
rest = dec // 16
if (rest == 0):
return digits[x]
return toHex(rest) + digits[x]
# numbers = [0, 11, 16, 32, 33, 41, 45, 678, 574893]
# for x in numbers:
# print(x, toHex(x))
# for x in numbers:
# print(x, hex(x))
#numbers = [0, 11, 16, 32, 33, 41, 45, 678, 574893]
for x in range(200):
print(x, toHex(x), hex(x), chr(x),)
# for x in range(200):
# print(x, hex(x))my_list[start_index:end_index]my_list[:] # This would be all of the items in my_list
my_list[:5] # This would be the items from index 0 to 4
my_list[5:] # This would be the items from index 5 to the end of the listdef append_exclamations(str_list):
for idx, item in enumerate(str_list):
str_list[idx] += "!">>> my_list = ["Matt", "Beej", "Sean"]
>>> append_exclamations(my_list)
>>> my_list
['Matt!', 'Beej!', 'Sean!']def append_exclamations(str_list):
# Create a new empty list that has the same length as the input list
loud_list = [None] * len(str_list)
for idx, item in enumerate(str_list):
# insert the modified string into the new list
loud_list[idx] = item + "!"
# Since we didn't modify the input list, we need to return the new list to
# the function caller
return loud_list>>> my_list = ["Matt", "Beej", "Sean"]
>>> my_new_louder_list = append_exclamations(my_list)
>>> my_list
['Matt', 'Beej', 'Sean']
>>> my_new_louder_list
['Matt!', 'Beej!', 'Sean!']
>>>import math
print(math.factorial(5))
# 120from math import factorial
print(factorial(5))
# 120from math import *
print(factorial(5))
# 120
print(pow(2, 3))
# 8.0import math as alias
print(alias.factorial(5))
# 120import math
print(dir(math))
# ['__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'comb', 'copysign', 'cos', 'cosh', 'degrees',class LinkedListNode:
def __init__(self, data=None, next=None):
self.data = data
self.next = nextclass LinkedList:
def __init__(self, head=None):
self.head = headclass LinkedList:
def __init__(self, head=None):
self.head = head
def append(self, data):
new_node = LinkedListNode(data)
if self.head:
current = self.head
while current.next:
current = current.next
current.next = new_node
else:
self.head = new_node>>> a = LinkedListNode(1)
>>> my_ll = LinkedList(a)
>>> my_ll.append(2)
>>> my_ll.append(3)
>>> my_ll.head.data
1
>>> my_ll.head.next.data
2
>>> my_ll.head.next.next.data
3
>>># -*- coding: utf-8 -*-
"""Linked Lists.ipynb
Automatically generated by Colaboratory.
Original file is located at
<https://colab.research.google.com/drive/17MD2e14fi7n95HTvy1K_ttM0FZSYnLmm>
# Linked Lists
- Non Contiguous abstract Data Structure
- Value (can be any value for our use we will just use numbers)
- Next (A pointer or reference to the next node in the list)Simple Singly Linked List Node Class
value -> int
next -> LinkedListNodeclass LinkedListNode:
def __init__(self, value):
self.value = value
self.next = None
def add_node(self, value):
# set current as a ref to self
current = self
# thile there is still more nodes
while current.next is not None:
# traverse to the next node
current = current.next
# create a new node and set the ref from current.next to the new node
current.next = LinkedListNode(value)
def insert_node(self, value, target):
# create a new node with the value provided
new_node = LinkedListNode(value)
# set a ref to the current node
current = self
# while the current nodes value is not the target
while current.value != target:
# traverse to the next node
current = current.next
# set the new nodes next pointer to point toward the current nodes next pointer
new_node.next = current.next
# set the current nodes next to point to the new node
current.next = new_node
def print_ll(linked_list_node):
current = linked_list_node
while current is not None:
print(current.value)
current = current.next
def add_to_ll_storage(linked_list_node):
current = linked_list_node
while current is not None:
ll_storage.append(current)
current = current.next
ll_storage = []
L1 = LinkedListNode(34)
L1.next = LinkedListNode(45)
L1.next.next = LinkedListNode(90)
L1.add_node(12)
print_ll(L1)
L1.add_node(24)
print('--------------------------------------------\n')
print_ll(L1)
print('--------------------------------------------\n')
L1.add_node(102)
print_ll(L1)
L1.insert_node(123, 90)
print('--------------------------------------------\n')
print_ll(L1)
L1.insert_node(678, 34)
print('--------------------------------------------\n')
print_ll(L1)
L1.insert_node(999, 102)
print('--------------------------------------------\n')
print_ll(L1)34
45
90
12
--------------------------------------------
34
45
90
12
24
--------------------------------------------
34
45
90
12
24
102
--------------------------------------------
34
45
90
123
12
24
102
--------------------------------------------
34
678
45
90
123
12
24
102
--------------------------------------------
34
678
45
90
123
12
24
102
999 Simple Doubly Linked List Node Class
value -> int
next -> LinkedListNode
prev -> LinkedListNodeGiven a reference to the head node of a singly-linked list, write a function
that reverses the linked list in place. The function should return the new head
of the reversed list.
In order to do this in O(1) space (in-place), you cannot make a new list, you
need to use the existing nodes.
In order to do this in O(n) time, you should only have to traverse the list
once.
*Note: If you get stuck, try drawing a picture of a small linked list and
running your function by hand. Does it actually work? Also, don't forget to
consider edge cases (like a list with only 1 or 0 elements).*
cn p
None [1] -> [2] ->[3] -> None
- setup a current variable pointing to the head of the list
- set up a prev variable pointing to None
- set up a next variable pointing to None
- while the current ref is not none
- set next to the current.next
- set the current.next to prev
- set prev to current
- set current to next
- return prevclass LinkedListNode:
def __init__(self, value):
self.value = value
self.next = None
self.prev = None
class LinkedListNode():
def __init__(self, value):
self.value = value
self.next = None
def reverse(head_of_list):
current = head_of_list
prev = None
next = None
while current:
next = current.next
current.next = prev
prev = current
current = next
return prev
class HashTableEntry:
"""
Linked List hash table key/value pair
"""
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
# Hash table can't have fewer than this many slots
MIN_CAPACITY = 8
[
0["Lou", 41] -> ["Bob", 41] -> None,
1["Steve", 41] -> None,
2["Jen", 41] -> None,
3["Dave", 41] -> None,
4None,
5["Hector", 34]-> None,
6["Lisa", 41] -> None,
7None,
8None,
9None
]
class HashTable:
"""
A hash table that with `capacity` buckets
that accepts string keys
Implement this.
"""
def __init__(self, capacity):
self.capacity = capacity # Number of buckets in the hash table
self.storage = [None] * capacity
self.item_count = 0
def get_num_slots(self):
"""
Return the length of the list you're using to hold the hash
table data. (Not the number of items stored in the hash table,
but the number of slots in the main list.)
One of the tests relies on this.
Implement this.
"""
# Your code here
def get_load_factor(self):
"""
Return the load factor for this hash table.
Implement this.
"""
return len(self.storage)
def djb2(self, key):
"""
DJB2 hash, 32-bit
Implement this, and/or FNV-1.
"""
str_key = str(key).encode()
hash = FNV_offset_basis_64
for b in str_key:
hash *= FNV_prime_64
hash ^= b
hash &= 0xffffffffffffffff # 64-bit hash
return hash
def hash_index(self, key):
"""
Take an arbitrary key and return a valid integer index
between within the storage capacity of the hash table.
"""
return self.djb2(key) % self.capacity
def put(self, key, value):
"""
Store the value with the given key.
Hash collisions should be handled with Linked List Chaining.
Implement this.
"""
index = self.hash_index(key)
current_entry = self.storage[index]
while current_entry is not None and current_entry.key != key:
current_entry = current_entry.next
if current_entry is not None:
current_entry.value = value
else:
new_entry = HashTableEntry(key, value)
new_entry.next = self.storage[index]
self.storage[index] = new_entry
def delete(self, key):
"""
Remove the value stored with the given key.
Print a warning if the key is not found.
Implement this.
"""
# Your code here
def get(self, key):
"""
Retrieve the value stored with the given key.
Returns None if the key is not found.
Implement this.
"""
# Your code hereAlgorithm Inorder(tree)
1. Traverse the left subtree, i.e., call Inorder(left-subtree)
2. Visit the root.
3. Traverse the right subtree, i.e., call Inorder(right-subtree)
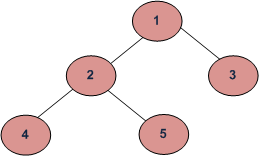
Algorithm Preorder(tree)
1. Visit the root.
2. Traverse the left subtree, i.e., call Preorder(left-subtree)
3. Traverse the right subtree, i.e., call Preorder(right-subtree) Algorithm Postorder(tree)
1. Traverse the left subtree, i.e., call Postorder(left-subtree)
2. Traverse the right subtree, i.e., call Postorder(right-subtree)
3. Visit the root.# Python program to for tree traversals
# A class that represents an individual node in a
# Binary Tree
class Node:
def __init__(self, key):
self.left = None
self.right = None
self.val = key
# A function to do inorder tree traversal
def printInorder(root):
if root:
# First recur on left child
printInorder(root.left)
# then print the data of node
print(root.val),
# now recur on right child
printInorder(root.right)
# A function to do postorder tree traversal
def printPostorder(root):
if root:
# First recur on left child
printPostorder(root.left)
# the recur on right child
printPostorder(root.right)
# now print the data of node
print(root.val),
# A function to do preorder tree traversal
def printPreorder(root):
if root:
# First print the data of node
print(root.val),
# Then recur on left child
printPreorder(root.left)
# Finally recur on right child
printPreorder(root.right)
# Driver code
root = Node(1)
root.left = Node(2)
root.right = Node(3)
root.left.left = Node(4)
root.left.right = Node(5)
print "Preorder traversal of binary tree is"
printPreorder(root)
print "\nInorder traversal of binary tree is"
printInorder(root)
print "\nPostorder traversal of binary tree is"
printPostorder(root)
// javascript program for different tree traversals
/* Class containing left and right child of current
node and key value*/
class Node {
constructor(val) {
this.key = val;
this.left = null;
this.right = null;
}
}
// Root of Binary Tree
var root = null;
/*
* Given a binary tree, print its nodes according to the "bottom-up" postorder
* traversal.
*/
function printPostorder(node) {
if (node == null)
return;
// first recur on left subtree
printPostorder(node.left);
// then recur on right subtree
printPostorder(node.right);
// now deal with the node
document.write(node.key + " ");
}
/* Given a binary tree, print its nodes in inorder */
function printInorder(node) {
if (node == null)
return;
/* first recur on left child */
printInorder(node.left);
/* then print the data of node */
document.write(node.key + " ");
/* now recur on right child */
printInorder(node.right);
}
/* Given a binary tree, print its nodes in preorder */
function printPreorder(node) {
if (node == null)
return;
/* first print data of node */
document.write(node.key + " ");
/* then recur on left sutree */
printPreorder(node.left);
/* now recur on right subtree */
printPreorder(node.right);
}
// Driver method
root = new Node(1);
root.left = new Node(2);
root.right = new Node(3);
root.left.left = new Node(4);
root.left.right = new Node(5);
document.write("Preorder traversal of binary tree is <br/>");
printPreorder(root);
document.write("<br/>Inorder traversal of binary tree is <br/>");
printInorder(root);
document.write("<br/>Postorder traversal of binary tree is <br/>");
printPostorder(root);
// This code is contributed by aashish1995




class BinaryTreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = Noneclass BSTNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = Noneclass BST:
def __init__(self, value):
self.root = BSTNode(value)
def insert(self, value):
self.root.insert(value)class BSTNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert(self, value):
if value < self.value:
if self.left is None:
self.left = BSTNode(value)
else:
self.left.insert(value)
else:
if self.right is None:
self.right = BSTNode(value)
else:
self.right.insert(value)class BST:
def __init__(self, value):
self.root = BSTNode(value)
def insert(self, value):
self.root.insert(value)
def search(self, value):
self.root.search(value)class BSTNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert(self, value):
if value < self.value:
if self.left is None:
self.left = BSTNode(value)
else:
self.left.insert(value)
else:
if self.right is None:
self.right = BSTNode(value)
else:
self.right.insert(value)
def search(self, target):
if self.value == target:
return self
elif target < self.value:
if self.left is None:
return False
else:
return self.left.search(target)
else:
if self.right is None:
return False
else:
return self.right.search(target)p.refendpp8,7,1,6,97,8,1,6,97,1,8,6,97,1,6,8,9 def bub_sort_datachange(self):
end = None
while end != self.start_node:
p = self.start_node
while p.ref != end:
q = p.ref
if p.item > q.item:
p.item, q.item = q.item, p.item
p = p.ref
end = p10,45,65,35,1 def bub_sort_linkchange(self):
end = None
while end != self.start_node:
r = p = self.start_node
while p.ref != end:
q = p.ref
if p.item > q.item:
p.ref = q.ref
q.ref = p
if p != self.start_node:
r.ref = q
else:
self.start_node = q
p,q = q,p
r = p
p = p.ref
end = p10,45,65,5,15,35,68p = 10
q = 5
em = none
newlist = nonep = 10
q = 15
em = 5
newlist = 5p = 45
q = 15
em = 10
newlist = 5, 10p = 45
q = 35
em = 15
newlist = 5, 10, 15p = 45
q = 68
em = 35
newlist = 5, 10, 15, 35p = 65
q = 68
em = 45
newlist = 5, 10, 15, 35, 45p = None
q = 68
em = 65
newlist = 5, 10, 15, 35, 45, 65p = None
q = None
em = 68
newlist = 5, 10, 15, 35, 45, 65, 68 def merge_helper(self, list2):
merged_list = LinkedList()
merged_list.start_node = self.merge_by_newlist(self.start_node, list2.start_node)
return merged_list
def merge_by_newlist(self, p, q):
if p.item <= q.item:
startNode = Node(p.item)
p = p.ref
else:
startNode = Node(q.item)
q = q.ref
em = startNode
while p is not None and q is not None:
if p.item <= q.item:
em.ref = Node(p.item)
p = p.ref
else:
em.ref = Node(q.item)
q = q.ref
em = em.ref
while p is not None:
em.ref = Node(p.item)
p = p.ref
em = em.ref
while q is not None:
em.ref = Node(q.item)
q = q.ref
em = em.ref
return startNode10,45,65,5,15,35,68p = 10
q = 5
em = none
newlist = nonep = 10
q = 15
start = 5
em = startp = 45
q = 15
em = 10p = 45
q = 35
em = 15p = 45
q = 68
em = 35p = 65
q = 68
em = 45
newlist = 5, 10, 15, 35, 45p = None
q = 68
em = 65
newlist = 5, 10, 15, 35, 45, 65p = None
q = None
em = 68
newlist = 5, 10, 15, 35, 45, 65, 68 def merge_helper2(self, list2):
merged_list = LinkedList()
merged_list.start_node = self.merge_by_linkChange(self.start_node, list2.start_node)
return merged_list
def merge_by_linkChange(self, p, q):
if p.item <= q.item:
startNode = Node(p.item)
p = p.ref
else:
startNode = Node(q.item)
q = q.ref
em = startNode
while p is not None and q is not None:
if p.item <= q.item:
em.ref = Node(p.item)
em = em.ref
p = p.ref
else:
em.ref = Node(q.item)
em = em.ref
q = q.ref
if p is None:
em.ref = q
else:
em.ref = p
return startNodenew_linked_list1 = LinkedList()
new_linked_list1.make_new_list()How many nodes do you want to create: 4
Enter the value for the node:12
Enter the value for the node:45
Enter the value for the node:32
Enter the value for the node:61new_linked_list2 = LinkedList()
new_linked_list2.make_new_list()How many nodes do you want to create: 4
Enter the value for the node:36
Enter the value for the node:41
Enter the value for the node:25
Enter the value for the node:9new_linked_list1. bub_sort_datachange()
new_linked_list2. bub_sort_datachange()list3 = new_linked_list1.merge_helper2(new_linked_list2)list3.traverse_list()9
12
25
32
36
41
45
61class LinkedListNode:
def __init__(self, data=None, next=None):
self.data = data
self.next = nextclass LinkedList:
def __init__(self, head=None):
self.head = headclass LinkedList:
def __init__(self, head=None):
self.head = head
def append(self, data):
new_node = LinkedListNode(data)
if self.head:
current = self.head
while current.next:
current = current.next
current.next = new_node
else:
self.head = new_node>>> a = LinkedListNode(1)
>>> my_ll = LinkedList(a)
>>> my_ll.append(2)
>>> my_ll.append(3)
>>> my_ll.head.data
1
>>> my_ll.head.next.data
2
>>> my_ll.head.next.next.data
3
>>>














