This article explores Python modules and Python packages, two mechanisms that facilitate modular programming.
Modular programming refers to the process of breaking a large, unwieldy programming task into separate, smaller, more manageable subtasks or modules. Individual modules can then be cobbled together like building blocks to create a larger application.
There are several advantages to modularizing code in a large application:
Simplicity: Rather than focusing on the entire problem at hand, a module typically focuses on one relatively small portion of the problem. If you’re working on a single module, you’ll have a smaller problem domain to wrap your head around. This makes development easier and less error-prone.
Maintainability: Modules are typically designed so that they enforce logical boundaries between different problem domains. If modules are written in a way that minimizes interdependency, there is decreased likelihood that modifications to a single module will have an impact on other parts of the program. (You may even be able to make changes to a module without having any knowledge of the application outside that module.) This makes it more viable for a team of many programmers to work collaboratively on a large application.
Reusability: Functionality defined in a single module can be easily reused (through an appropriately defined interface) by other parts of the application. This eliminates the need to duplicate code.
Scoping: Modules typically define a separate , which helps avoid collisions between identifiers in different areas of a program. (One of the tenets in the is Namespaces are one honking great idea—let’s do more of those!)
Functions, modules and packages are all constructs in Python that promote code modularization.
Free PDF Download:
Python Modules: Overview
There are actually three different ways to define a module in Python:
A module can be written in Python itself.
A module can be written in C and loaded dynamically at run-time, like the re () module.
A built-in module is intrinsically contained in the interpreter, like the .
A module’s contents are accessed the same way in all three cases: with the import statement.
Here, the focus will mostly be on modules that are written in Python. The cool thing about modules written in Python is that they are exceedingly straightforward to build. All you need to do is create a file that contains legitimate Python code and then give the file a name with a .py extension. That’s it! No special syntax or voodoo is necessary.
For example, suppose you have created a file called mod.py containing the following:
mod.py
Several objects are defined in mod.py:
Assuming mod.py is in an appropriate location, which you will learn more about shortly, these objects can be accessed by importing the module as follows:>>>
The Module Search Path
Continuing with the above example, let’s take a look at what happens when Python executes the statement:
When the interpreter executes the above import statement, it searches for mod.py in a of directories assembled from the following sources:
The directory from which the input script was run or the current directory if the interpreter is being run interactively
The list of directories contained in the environment variable, if it is set. (The format for PYTHONPATH is OS-dependent but should mimic the PATH environment variable.)
The resulting search path is accessible in the Python variable sys.path, which is obtained from a module named sys:>>>
Note: The exact contents of sys.path are installation-dependent. The above will almost certainly look slightly different on your computer.
Thus, to ensure your module is found, you need to do one of the following:
Put mod.py in the directory where the input script is located or the current directory, if interactive
Modify the PYTHONPATH environment variable to contain the directory where mod.py is located before starting the interpreter
There is actually one additional option: you can put the module file in any directory of your choice and then modify sys.path at run-time so that it contains that directory. For example, in this case, you could put mod.py in directory C:\Users\john and then issue the following statements:>>>
Once a module has been imported, you can determine the location where it was found with the module’s __file__ attribute:>>>
The directory portion of __file__ should be one of the directories in sys.path.
The import Statement
Module contents are made available to the caller with the import statement. The import statement takes many different forms, shown below.
import <module_name>
The simplest form is the one already shown above:
Note that this does not make the module contents directly accessible to the caller. Each module has its own private symbol table, which serves as the global symbol table for all objects defined in the module. Thus, a module creates a separate namespace, as already noted.
The statement import <module_name> only places <module_name> in the caller’s symbol table. The objects that are defined in the module remain in the module’s private symbol table.
From the caller, objects in the module are only accessible when prefixed with <module_name> via dot notation, as illustrated below.
After the following import statement, mod is placed into the local symbol table. Thus, mod has meaning in the caller’s local context:>>>
But s and foo remain in the module’s private symbol table and are not meaningful in the local context:>>>
To be accessed in the local context, names of objects defined in the module must be prefixed by mod:>>>
Several comma-separated modules may be specified in a single import statement:
from <module_name> import <name(s)>
An alternate form of the import statement allows individual objects from the module to be imported directly into the caller’s symbol table:
Following execution of the above statement, <name(s)> can be referenced in the caller’s environment without the <module_name> prefix:>>>
Because this form of import places the object names directly into the caller’s symbol table, any objects that already exist with the same name will be overwritten:>>>
It is even possible to indiscriminately import everything from a module at one fell swoop:
This will place the names of all objects from <module_name> into the local symbol table, with the exception of any that begin with the underscore (_) character.
For example:>>>
This isn’t necessarily recommended in large-scale production code. It’s a bit dangerous because you are entering names into the local symbol table en masse. Unless you know them all well and can be confident there won’t be a conflict, you have a decent chance of overwriting an existing name inadvertently. However, this syntax is quite handy when you are just mucking around with the interactive interpreter, for testing or discovery purposes, because it quickly gives you access to everything a module has to offer without a lot of typing.
from <module_name> import <name> as <alt_name>
It is also possible to import individual objects but enter them into the local symbol table with alternate names:
This makes it possible to place names directly into the local symbol table but avoid conflicts with previously existing names:>>>
import <module_name> as <alt_name>
You can also import an entire module under an alternate name:
>>>
Module contents can be imported from within a . In that case, the import does not occur until the function is called:>>>
However, Python 3 does not allow the indiscriminate import * syntax from within a function:>>>
Lastly, a clause can be used to guard against unsuccessful import attempts:>>>
>>>
The dir() Function
The built-in function dir() returns a list of defined names in a namespace. Without arguments, it produces an alphabetically sorted list of names in the current local symbol table:>>>
Note how the first call to dir() above lists several names that are automatically defined and already in the namespace when the interpreter starts. As new names are defined (qux, Bar, x), they appear on subsequent invocations of dir().
This can be useful for identifying what exactly has been added to the namespace by an import statement:>>>
When given an argument that is the name of a module, dir() lists the names defined in the module:>>>
>>>
Executing a Module as a Script
Any .py file that contains a module is essentially also a Python script, and there isn’t any reason it can’t be executed like one.
Here again is mod.py as it was defined above:
mod.py
This can be run as a script:
There are no errors, so it apparently worked. Granted, it’s not very interesting. As it is written, it only defines objects. It doesn’t do anything with them, and it doesn’t generate any output.
Let’s modify the above Python module so it does generate some output when run as a script:
mod.py
Now it should be a little more interesting:
Unfortunately, now it also generates output when imported as a module:>>>
This is probably not what you want. It isn’t usual for a module to generate output when it is imported.
Wouldn’t it be nice if you could distinguish between when the file is loaded as a module and when it is run as a standalone script?
Ask and ye shall receive.
When a .py file is imported as a module, Python sets the special dunder variable to the name of the module. However, if a file is run as a standalone script, __name__ is (creatively) set to the string '__main__'. Using this fact, you can discern which is the case at run-time and alter behavior accordingly:
mod.py
Now, if you run as a script, you get output:
But if you import as a module, you don’t:>>>
Modules are often designed with the capability to run as a standalone script for purposes of testing the functionality that is contained within the module. This is referred to as . For example, suppose you have created a module fact.py containing a factorial function, as follows:
fact.py
The file can be treated as a module, and the fact() function imported:>>>
But it can also be run as a standalone by passing an integer argument on the command-line for testing:
Reloading a Module
For reasons of efficiency, a module is only loaded once per interpreter session. That is fine for function and class definitions, which typically make up the bulk of a module’s contents. But a module can contain executable statements as well, usually for initialization. Be aware that these statements will only be executed the first time a module is imported.
Consider the following file mod.py:
mod.py
>>>
The print() statement is not executed on subsequent imports. (For that matter, neither is the assignment statement, but as the final display of the value of mod.a shows, that doesn’t matter. Once the assignment is made, it sticks.)
If you make a change to a module and need to reload it, you need to either restart the interpreter or use a function called reload() from module importlib:>>>
Python Packages
Suppose you have developed a very large application that includes many modules. As the number of modules grows, it becomes difficult to keep track of them all if they are dumped into one location. This is particularly so if they have similar names or functionality. You might wish for a means of grouping and organizing them.
Packages allow for a hierarchical structuring of the module namespace using dot notation. In the same way that modules help avoid collisions between global variable names, packages help avoid collisions between module names.
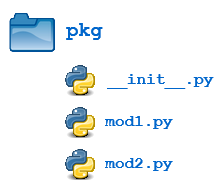
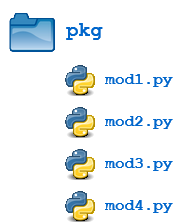
Creating a package is quite straightforward, since it makes use of the operating system’s inherent hierarchical file structure. Consider the following arrangement:
Here, there is a directory named pkg that contains two modules, mod1.py and mod2.py. The contents of the modules are:
mod1.py
mod2.py
Given this structure, if the pkg directory resides in a location where it can be found (in one of the directories contained in sys.path), you can refer to the two modules with dot notation (pkg.mod1, pkg.mod2) and import them with the syntax you are already familiar with:
>>>
>>>
>>>
You can import modules with these statements as well:
>>>
You can technically import the package as well:>>>
But this is of little avail. Though this is, strictly speaking, a syntactically correct Python statement, it doesn’t do much of anything useful. In particular, it does not place any of the modules in pkg into the local namespace:>>>
To actually import the modules or their contents, you need to use one of the forms shown above.
Package Initialization
If a file named __init__.py is present in a package directory, it is invoked when the package or a module in the package is imported. This can be used for execution of package initialization code, such as initialization of package-level data.
For example, consider the following __init__.py file:
__init__.py
Let’s add this file to the pkg directory from the above example:
Now when the package is imported, the global list A is initialized:>>>
A module in the package can access the global variable by importing it in turn:
mod1.py
>>>
__init__.py can also be used to effect automatic importing of modules from a package. For example, earlier you saw that the statement import pkg only places the name pkg in the caller’s local symbol table and doesn’t import any modules. But if __init__.py in the pkg directory contains the following:
__init__.py
then when you execute import pkg, modules mod1 and mod2 are imported automatically:>>>
Note: Much of the Python documentation states that an __init__.py file must be present in the package directory when creating a package. This was once true. It used to be that the very presence of __init__.py signified to Python that a package was being defined. The file could contain initialization code or even be empty, but it had to be present.
Starting with Python 3.3, were introduced. These allow for the creation of a package without any __init__.py file. Of course, it can still be present if package initialization is needed. But it is no longer required.
Importing * From a Package
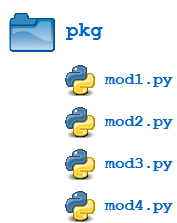
For the purposes of the following discussion, the previously defined package is expanded to contain some additional modules:
There are now four modules defined in the pkg directory. Their contents are as shown below:
mod1.py
mod2.py
mod3.py
mod4.py
(Imaginative, aren’t they?)
You have already seen that when import * is used for a module, all objects from the module are imported into the local symbol table, except those whose names begin with an underscore, as always:>>>
The analogous statement for a package is this:
What does that do?>>>
Hmph. Not much. You might have expected (assuming you had any expectations at all) that Python would dive down into the package directory, find all the modules it could, and import them all. But as you can see, by default that is not what happens.
Instead, Python follows this convention: if the __init__.py file in the package directory contains a list named __all__, it is taken to be a list of modules that should be imported when the statement from <package_name> import * is encountered.
For the present example, suppose you create an __init__.py in the pkg directory like this:
pkg/__init__.py
Now from pkg import * imports all four modules:>>>
Using import * still isn’t considered terrific form, any more for packages than for modules. But this facility at least gives the creator of the package some control over what happens when import * is specified. (In fact, it provides the capability to disallow it entirely, simply by declining to define __all__ at all. As you have seen, the default behavior for packages is to import nothing.)
By the way, __all__ can be defined in a module as well and serves the same purpose: to control what is imported with import *. For example, modify mod1.py as follows:
pkg/mod1.py
Now an import * statement from pkg.mod1 will only import what is contained in __all__:>>>
foo() (the function) is now defined in the local namespace, but Foo (the class) is not, because the latter is not in __all__.
In summary, __all__ is used by both packages and modules to control what is imported when import * is specified. But the default behavior differs:
For a package, when __all__ is not defined, import * does not import anything.
For a module, when __all__ is not defined, import * imports everything (except—you guessed it—names starting with an underscore).
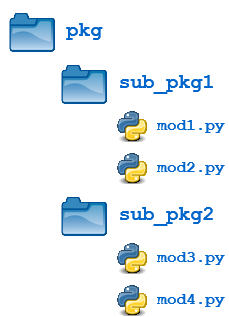
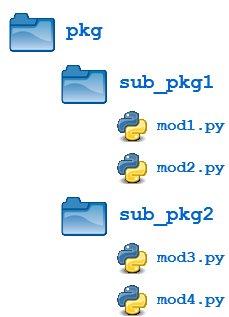
Packages can contain nested subpackages to arbitrary depth. For example, let’s make one more modification to the example package directory as follows:
The four modules (mod1.py, mod2.py, mod3.py and mod4.py) are defined as previously. But now, instead of being lumped together into the pkg directory, they are split out into two subpackage directories, sub_pkg1 and sub_pkg2.
Importing still works the same as shown previously. Syntax is similar, but additional dot notation is used to separate package name from subpackage name:>>>
In addition, a module in one subpackage can reference objects in a sibling subpackage (in the event that the sibling contains some functionality that you need). For example, suppose you want to import and execute function foo() (defined in module mod1) from within module mod3. You can either use an absolute import:
pkg/sub__pkg2/mod3.py
>>>
Or you can use a relative import, where .. refers to the package one level up. From within mod3.py, which is in subpackage sub_pkg2,
.. evaluates to the parent package (pkg), and
..sub_pkg1 evaluates to subpackage sub_pkg1 of the parent package.
pkg/sub__pkg2/mod3.py
>>>
In this tutorial, you covered the following topics:
How to create a Python module
Locations where the Python interpreter searches for a module
How to obtain access to the objects defined in a module with the import statement
Free PDF Download:
This will hopefully allow you to better understand how to gain access to the functionality available in the many third-party and built-in modules available in Python.
Additionally, if you are developing your own application, creating your own modules and packages will help you organize and modularize your code, which makes coding, maintenance, and debugging easier.
If you want to learn more, check out the following documentation at Python.org:
— Top-level script environment
'__main__' is the name of the scope in which top-level code executes. A module’s __name__ is set equal to '__main__' when read from standard input, a script, or from an interactive prompt.
A module can discover whether or not it is running in the main scope by checking its own __name__, which allows a common idiom for conditionally executing code in a module when it is run as a script or with python -m but not when it is imported:
For a package, the same effect can be achieved by including a __main__.py module, the contents of which will be executed when the module is run
. The import system
Python code in one gains access to the code in another module by the process of it. The statement is the most common way of invoking the import machinery, but it is not the only way. Functions such as and built-in can also be used to invoke the import machinery.
The statement combines two operations; it searches for the named module, then it binds the results of that search to a name in the local scope. The search operation of the import statement is defined as a call to the function, with the appropriate arguments. The return value of is used to perform the name binding operation of the import statement. See the import statement for the exact details of that name binding operation.
A direct call to performs only the module search and, if found, the module creation operation. While certain side-effects may occur, such as the importing of parent packages, and the updating of various caches (including ), only the statement performs a name binding operation.
When an statement is executed, the standard builtin function is called. Other mechanisms for invoking the import system (such as ) may choose to bypass and use their own solutions to implement import semantics.
When a module is first imported, Python searches for the module and if found, it creates a module object , initializing it. If the named module cannot be found, a is raised. Python implements various strategies to search for the named module when the import machinery is invoked. These strategies can be modified and extended by using various hooks described in the sections below.
Changed in version 3.3: The import system has been updated to fully implement the second phase of . There is no longer any implicit import machinery - the full import system is exposed through . In addition, native namespace package support has been implemented (see ).
The module provides a rich API for interacting with the import system. For example provides a recommended, simpler API than built-in for invoking the import machinery. Refer to the library documentation for additional detail.
Python has only one type of module object, and all modules are of this type, regardless of whether the module is implemented in Python, C, or something else. To help organize modules and provide a naming hierarchy, Python has a concept of .
You can think of packages as the directories on a file system and modules as files within directories, but don’t take this analogy too literally since packages and modules need not originate from the file system. For the purposes of this documentation, we’ll use this convenient analogy of directories and files. Like file system directories, packages are organized hierarchically, and packages may themselves contain subpackages, as well as regular modules.
It’s important to keep in mind that all packages are modules, but not all modules are packages. Or put another way, packages are just a special kind of module. Specifically, any module that contains a __path__ attribute is considered a package.
All modules have a name. Subpackage names are separated from their parent package name by a dot, akin to Python’s standard attribute access syntax. Thus you might have a module called and a package called , which in turn has a subpackage called and a module within that subpackage called email.mime.text.
5.2.1. Regular packages
Python defines two types of packages, and . Regular packages are traditional packages as they existed in Python 3.2 and earlier. A regular package is typically implemented as a directory containing an __init__.py file. When a regular package is imported, this __init__.py file is implicitly executed, and the objects it defines are bound to names in the package’s namespace. The __init__.py file can contain the same Python code that any other module can contain, and Python will add some additional attributes to the module when it is imported.
For example, the following file system layout defines a top level parent package with three subpackages:
Importing parent.one will implicitly execute parent/__init__.py and parent/one/__init__.py. Subsequent imports of parent.two or parent.three will execute parent/two/__init__.py and parent/three/__init__.py respectively.
5.2.2. Namespace packages
A namespace package is a composite of various , where each portion contributes a subpackage to the parent package. Portions may reside in different locations on the file system. Portions may also be found in zip files, on the network, or anywhere else that Python searches during import. Namespace packages may or may not correspond directly to objects on the file system; they may be virtual modules that have no concrete representation.
Namespace packages do not use an ordinary list for their __path__ attribute. They instead use a custom iterable type which will automatically perform a new search for package portions on the next import attempt within that package if the path of their parent package (or for a top level package) changes.
With namespace packages, there is no parent/__init__.py file. In fact, there may be multiple parent directories found during import search, where each one is provided by a different portion. Thus parent/one may not be physically located next to parent/two. In this case, Python will create a namespace package for the top-level parent package whenever it or one of its subpackages is imported.
See also for the namespace package specification.
To begin the search, Python needs the name of the module (or package, but for the purposes of this discussion, the difference is immaterial) being imported. This name may come from various arguments to the statement, or from the parameters to the or functions.
This name will be used in various phases of the import search, and it may be the dotted path to a submodule, e.g. foo.bar.baz. In this case, Python first tries to import foo, then foo.bar, and finally foo.bar.baz. If any of the intermediate imports fail, a is raised.
5.3.1. The module cache
The first place checked during import search is . This mapping serves as a cache of all modules that have been previously imported, including the intermediate paths. So if foo.bar.baz was previously imported, will contain entries for foo, foo.bar, and foo.bar.baz. Each key will have as its value the corresponding module object.
During import, the module name is looked up in and if present, the associated value is the module satisfying the import, and the process completes. However, if the value is None, then a is raised. If the module name is missing, Python will continue searching for the module.
is writable. Deleting a key may not destroy the associated module (as other modules may hold references to it), but it will invalidate the cache entry for the named module, causing Python to search anew for the named module upon its next import. The key can also be assigned to None, forcing the next import of the module to result in a .
Beware though, as if you keep a reference to the module object, invalidate its cache entry in , and then re-import the named module, the two module objects will not be the same. By contrast, will reuse the same module object, and simply reinitialise the module contents by rerunning the module’s code.
5.3.2. Finders and loaders
If the named module is not found in , then Python’s import protocol is invoked to find and load the module. This protocol consists of two conceptual objects, and . A finder’s job is to determine whether it can find the named module using whatever strategy it knows about. Objects that implement both of these interfaces are referred to as - they return themselves when they find that they can load the requested module.
Python includes a number of default finders and importers. The first one knows how to locate built-in modules, and the second knows how to locate frozen modules. A third default finder searches an for modules. The is a list of locations that may name file system paths or zip files. It can also be extended to search for any locatable resource, such as those identified by URLs.
The import machinery is extensible, so new finders can be added to extend the range and scope of module searching.
Finders do not actually load modules. If they can find the named module, they return a module spec, an encapsulation of the module’s import-related information, which the import machinery then uses when loading the module.
The following sections describe the protocol for finders and loaders in more detail, including how you can create and register new ones to extend the import machinery.
Changed in version 3.4: In previous versions of Python, finders returned directly, whereas now they return module specs which contain loaders. Loaders are still used during import but have fewer responsibilities.
5.3.3. Import hooks
The import machinery is designed to be extensible; the primary mechanism for this are the import hooks. There are two types of import hooks: meta hooks and import path hooks.
Meta hooks are called at the start of import processing, before any other import processing has occurred, other than cache look up. This allows meta hooks to override processing, frozen modules, or even built-in modules. Meta hooks are registered by adding new finder objects to , as described below.
Import path hooks are called as part of (or package.__path__) processing, at the point where their associated path item is encountered. Import path hooks are registered by adding new callables to as described below.
5.3.4. The meta path
When the named module is not found in , Python next searches , which contains a list of meta path finder objects. These finders are queried in order to see if they know how to handle the named module. Meta path finders must implement a method called which takes three arguments: a name, an import path, and (optionally) a target module. The meta path finder can use any strategy it wants to determine whether it can handle the named module or not.
If the meta path finder knows how to handle the named module, it returns a spec object. If it cannot handle the named module, it returns None. If processing reaches the end of its list without returning a spec, then a is raised. Any other exceptions raised are simply propagated up, aborting the import process.
The method of meta path finders is called with two or three arguments. The first is the fully qualified name of the module being imported, for example foo.bar.baz. The second argument is the path entries to use for the module search. For top-level modules, the second argument is None, but for submodules or subpackages, the second argument is the value of the parent package’s __path__ attribute. If the appropriate __path__ attribute cannot be accessed, a is raised. The third argument is an existing module object that will be the target of loading later. The import system passes in a target module only during reload.
The meta path may be traversed multiple times for a single import request. For example, assuming none of the modules involved has already been cached, importing foo.bar.baz will first perform a top level import, calling mpf.find_spec("foo", None, None) on each meta path finder (mpf). After foo has been imported, foo.bar will be imported by traversing the meta path a second time, calling mpf.find_spec("foo.bar", foo.__path__, None). Once foo.bar has been imported, the final traversal will call mpf.find_spec("foo.bar.baz", foo.bar.__path__, None).
Some meta path finders only support top level imports. These importers will always return None when anything other than None is passed as the second argument.
Python’s default has three meta path finders, one that knows how to import built-in modules, one that knows how to import frozen modules, and one that knows how to import modules from an (i.e. the ).
Changed in version 3.4: The method of meta path finders replaced , which is now deprecated. While it will continue to work without change, the import machinery will try it only if the finder does not implement find_spec().
If and when a module spec is found, the import machinery will use it (and the loader it contains) when loading the module. Here is an approximation of what happens during the loading portion of import:
Note the following details:
If there is an existing module object with the given name in , import will have already returned it.
The module will exist in before the loader executes the module code. This is crucial because the module code may (directly or indirectly) import itself; adding it to beforehand prevents unbounded recursion in the worst case and multiple loading in the best.
Changed in version 3.4: The import system has taken over the boilerplate responsibilities of loaders. These were previously performed by the method.
Module loaders provide the critical function of loading: module execution. The import machinery calls the method with a single argument, the module object to execute. Any value returned from is ignored.
Loaders must satisfy the following requirements:
If the module is a Python module (as opposed to a built-in module or a dynamically loaded extension), the loader should execute the module’s code in the module’s global name space (module.__dict__).
If the loader cannot execute the module, it should raise an , although any other exception raised during will be propagated.
In many cases, the finder and loader can be the same object; in such cases the method would just return a spec with the loader set to self.
Module loaders may opt in to creating the module object during loading by implementing a method. It takes one argument, the module spec, and returns the new module object to use during loading. create_module() does not need to set any attributes on the module object. If the method returns None, the import machinery will create the new module itself.
New in version 3.4: The method of loaders.
Changed in version 3.4: The method was replaced by and the import machinery assumed all the boilerplate responsibilities of loading.
For compatibility with existing loaders, the import machinery will use the load_module() method of loaders if it exists and the loader does not also implement exec_module(). However, load_module() has been deprecated and loaders should implement exec_module() instead.
The load_module() method must implement all the boilerplate loading functionality described above in addition to executing the module. All the same constraints apply, with some additional clarification:
If there is an existing module object with the given name in , the loader must use that existing module. (Otherwise, will not work correctly.) If the named module does not exist in , the loader must create a new module object and add it to .
The module must exist in before the loader executes the module code, to prevent unbounded recursion or multiple loading.
Changed in version 3.5: A is raised when exec_module() is defined but create_module() is not.
Changed in version 3.6: An is raised when exec_module() is defined but create_module() is not.
5.4.2. Submodules
When a submodule is loaded using any mechanism (e.g. importlib APIs, the import or import-from statements, or built-in __import__()) a binding is placed in the parent module’s namespace to the submodule object. For example, if package spam has a submodule foo, after importing spam.foo, spam will have an attribute foo which is bound to the submodule. Let’s say you have the following directory structure:
and spam/__init__.py has the following lines in it:
then executing the following puts a name binding to foo and bar in the spam module:>>>
Given Python’s familiar name binding rules this might seem surprising, but it’s actually a fundamental feature of the import system. The invariant holding is that if you have sys.modules['spam'] and sys.modules['spam.foo'] (as you would after the above import), the latter must appear as the foo attribute of the former.
5.4.3. Module spec
The import machinery uses a variety of information about each module during import, especially before loading. Most of the information is common to all modules. The purpose of a module’s spec is to encapsulate this import-related information on a per-module basis.
Using a spec during import allows state to be transferred between import system components, e.g. between the finder that creates the module spec and the loader that executes it. Most importantly, it allows the import machinery to perform the boilerplate operations of loading, whereas without a module spec the loader had that responsibility.
The module’s spec is exposed as the __spec__ attribute on a module object. See for details on the contents of the module spec.
New in version 3.4.
5.4.4. Import-related module attributes
The import machinery fills in these attributes on each module object during loading, based on the module’s spec, before the loader executes the module.__name__
The __name__ attribute must be set to the fully-qualified name of the module. This name is used to uniquely identify the module in the import system.__loader__
The __loader__ attribute must be set to the loader object that the import machinery used when loading the module. This is mostly for introspection, but can be used for additional loader-specific functionality, for example getting data associated with a loader.__package__
The module’s __package__ attribute must be set. Its value must be a string, but it can be the same value as its __name__. When the module is a package, its __package__ value should be set to its __name__. When the module is not a package, __package__ should be set to the empty string for top-level modules, or for submodules, to the parent package’s name. See for further details.
This attribute is used instead of __name__ to calculate explicit relative imports for main modules, as defined in . It is expected to have the same value as __spec__.parent.
Changed in version 3.6: The value of __package__ is expected to be the same as __spec__.parent.__spec__
The __spec__ attribute must be set to the module spec that was used when importing the module. Setting __spec__ appropriately applies equally to . The one exception is __main__, where __spec__ is .
When __package__ is not defined, __spec__.parent is used as a fallback.
New in version 3.4.
Changed in version 3.6: __spec__.parent is used as a fallback when __package__ is not defined.__path__
If the module is a package (either regular or namespace), the module object’s __path__ attribute must be set. The value must be iterable, but may be empty if __path__ has no further significance. If __path__ is not empty, it must produce strings when iterated over. More details on the semantics of __path__ are given .
Non-package modules should not have a __path__ attribute.__file____cached__
__file__ is optional. If set, this attribute’s value must be a string. The import system may opt to leave __file__ unset if it has no semantic meaning (e.g. a module loaded from a database).
If __file__ is set, it may also be appropriate to set the __cached__ attribute which is the path to any compiled version of the code (e.g. byte-compiled file). The file does not need to exist to set this attribute; the path can simply point to where the compiled file would exist (see ).
It is also appropriate to set __cached__ when __file__ is not set. However, that scenario is quite atypical. Ultimately, the loader is what makes use of __file__ and/or __cached__. So if a loader can load from a cached module but otherwise does not load from a file, that atypical scenario may be appropriate.
5.4.5. module.__path__
By definition, if a module has a __path__ attribute, it is a package.
A package’s __path__ attribute is used during imports of its subpackages. Within the import machinery, it functions much the same as , i.e. providing a list of locations to search for modules during import. However, __path__ is typically much more constrained than .
__path__ must be an iterable of strings, but it may be empty. The same rules used for also apply to a package’s __path__, and (described below) are consulted when traversing a package’s __path__.
A package’s __init__.py file may set or alter the package’s __path__ attribute, and this was typically the way namespace packages were implemented prior to . With the adoption of , namespace packages no longer need to supply __init__.py files containing only __path__ manipulation code; the import machinery automatically sets __path__ correctly for the namespace package.
5.4.6. Module reprs
By default, all modules have a usable repr, however depending on the attributes set above, and in the module’s spec, you can more explicitly control the repr of module objects.
If the module has a spec (__spec__), the import machinery will try to generate a repr from it. If that fails or there is no spec, the import system will craft a default repr using whatever information is available on the module. It will try to use the module.__name__, module.__file__, and module.__loader__ as input into the repr, with defaults for whatever information is missing.
Here are the exact rules used:
If the module has a __spec__ attribute, the information in the spec is used to generate the repr. The “name”, “loader”, “origin”, and “has_location” attributes are consulted.
If the module has a __file__ attribute, this is used as part of the module’s repr.
Changed in version 3.4: Use of has been deprecated and the module spec is now used by the import machinery to generate a module repr.
For backward compatibility with Python 3.3, the module repr will be generated by calling the loader’s method, if defined, before trying either approach described above. However, the method is deprecated.
5.4.7. Cached bytecode invalidation
Before Python loads cached bytecode from a .pyc file, it checks whether the cache is up-to-date with the source .py file. By default, Python does this by storing the source’s last-modified timestamp and size in the cache file when writing it. At runtime, the import system then validates the cache file by checking the stored metadata in the cache file against the source’s metadata.
Python also supports “hash-based” cache files, which store a hash of the source file’s contents rather than its metadata. There are two variants of hash-based .pyc files: checked and unchecked. For checked hash-based .pyc files, Python validates the cache file by hashing the source file and comparing the resulting hash with the hash in the cache file. If a checked hash-based cache file is found to be invalid, Python regenerates it and writes a new checked hash-based cache file. For unchecked hash-based .pyc files, Python simply assumes the cache file is valid if it exists. Hash-based .pyc files validation behavior may be overridden with the flag.
Changed in version 3.7: Added hash-based .pyc files. Previously, Python only supported timestamp-based invalidation of bytecode caches.
5.5. The Path Based Finder
As mentioned previously, Python comes with several default meta path finders. One of these, called the (), searches an , which contains a list of . Each path entry names a location to search for modules.
The path based finder itself doesn’t know how to import anything. Instead, it traverses the individual path entries, associating each of them with a path entry finder that knows how to handle that particular kind of path.
The default set of path entry finders implement all the semantics for finding modules on the file system, handling special file types such as Python source code (.py files), Python byte code (.pyc files) and shared libraries (e.g. .so files). When supported by the module in the standard library, the default path entry finders also handle loading all of these file types (other than shared libraries) from zipfiles.
Path entries need not be limited to file system locations. They can refer to URLs, database queries, or any other location that can be specified as a string.
The path based finder provides additional hooks and protocols so that you can extend and customize the types of searchable path entries. For example, if you wanted to support path entries as network URLs, you could write a hook that implements HTTP semantics to find modules on the web. This hook (a callable) would return a supporting the protocol described below, which was then used to get a loader for the module from the web.
A word of warning: this section and the previous both use the term finder, distinguishing between them by using the terms and . These two types of finders are very similar, support similar protocols, and function in similar ways during the import process, but it’s important to keep in mind that they are subtly different. In particular, meta path finders operate at the beginning of the import process, as keyed off the traversal.
By contrast, path entry finders are in a sense an implementation detail of the path based finder, and in fact, if the path based finder were to be removed from , none of the path entry finder semantics would be invoked.
5.5.1. Path entry finders
The is responsible for finding and loading Python modules and packages whose location is specified with a string . Most path entries name locations in the file system, but they need not be limited to this.
As a meta path finder, the implements the protocol previously described, however it exposes additional hooks that can be used to customize how modules are found and loaded from the .
Three variables are used by the , , and . The __path__ attributes on package objects are also used. These provide additional ways that the import machinery can be customized.
contains a list of strings providing search locations for modules and packages. It is initialized from the PYTHONPATH environment variable and various other installation- and implementation-specific defaults. Entries in can name directories on the file system, zip files, and potentially other “locations” (see the module) that should be searched for modules, such as URLs, or database queries. Only strings and bytes should be present on ; all other data types are ignored. The encoding of bytes entries is determined by the individual .
The is a , so the import machinery begins the search by calling the path based finder’s method as described previously. When the path argument to is given, it will be a list of string paths to traverse - typically a package’s __path__ attribute for an import within that package. If the path argument is None, this indicates a top level import and is used.
The path based finder iterates over every entry in the search path, and for each of these, looks for an appropriate () for the path entry. Because this can be an expensive operation (e.g. there may be stat() call overheads for this search), the path based finder maintains a cache mapping path entries to path entry finders. This cache is maintained in (despite the name, this cache actually stores finder objects rather than being limited to objects). In this way, the expensive search for a particular location’s need only be done once. User code is free to remove cache entries from forcing the path based finder to perform the path entry search again .
If the path entry is not present in the cache, the path based finder iterates over every callable in . Each of the in this list is called with a single argument, the path entry to be searched. This callable may either return a that can handle the path entry, or it may raise . An is used by the path based finder to signal that the hook cannot find a for that . The exception is ignored and iteration continues. The hook should expect either a string or bytes object; the encoding of bytes objects is up to the hook (e.g. it may be a file system encoding, UTF-8, or something else), and if the hook cannot decode the argument, it should raise .
If iteration ends with no being returned, then the path based finder’s method will store None in (to indicate that there is no finder for this path entry) and return None, indicating that this could not find the module.
If a is returned by one of the callables on , then the following protocol is used to ask the finder for a module spec, which is then used when loading the module.
The current working directory – denoted by an empty string – is handled slightly differently from other entries on . First, if the current working directory is found to not exist, no value is stored in . Second, the value for the current working directory is looked up fresh for each module lookup. Third, the path used for and returned by will be the actual current working directory and not the empty string.
5.5.2. Path entry finder protocol
In order to support imports of modules and initialized packages and also to contribute portions to namespace packages, path entry finders must implement the method.
takes two arguments: the fully qualified name of the module being imported, and the (optional) target module. find_spec() returns a fully populated spec for the module. This spec will always have “loader” set (with one exception).
To indicate to the import machinery that the spec represents a namespace , the path entry finder sets “submodule_search_locations” to a list containing the portion.
Changed in version 3.4: replaced and , both of which are now deprecated, but will be used if find_spec() is not defined.
Older path entry finders may implement one of these two deprecated methods instead of find_spec(). The methods are still respected for the sake of backward compatibility. However, if find_spec() is implemented on the path entry finder, the legacy methods are ignored.
takes one argument, the fully qualified name of the module being imported. find_loader() returns a 2-tuple where the first item is the loader and the second item is a namespace .
For backwards compatibility with other implementations of the import protocol, many path entry finders also support the same, traditional find_module() method that meta path finders support. However path entry finder find_module() methods are never called with a path argument (they are expected to record the appropriate path information from the initial call to the path hook).
The find_module() method on path entry finders is deprecated, as it does not allow the path entry finder to contribute portions to namespace packages. If both find_loader() and find_module() exist on a path entry finder, the import system will always call find_loader() in preference to find_module().
5.6. Replacing the standard import system
The most reliable mechanism for replacing the entire import system is to delete the default contents of , replacing them entirely with a custom meta path hook.
If it is acceptable to only alter the behaviour of import statements without affecting other APIs that access the import system, then replacing the builtin function may be sufficient. This technique may also be employed at the module level to only alter the behaviour of import statements within that module.
To selectively prevent the import of some modules from a hook early on the meta path (rather than disabling the standard import system entirely), it is sufficient to raise directly from instead of returning None. The latter indicates that the meta path search should continue, while raising an exception terminates it immediately.
5.7. Package Relative Imports
Relative imports use leading dots. A single leading dot indicates a relative import, starting with the current package. Two or more leading dots indicate a relative import to the parent(s) of the current package, one level per dot after the first. For example, given the following package layout:
In either subpackage1/moduleX.py or subpackage1/__init__.py, the following are valid relative imports:
Absolute imports may use either the import <> or from <> import <> syntax, but relative imports may only use the second form; the reason for this is that:
should expose XXX.YYY.ZZZ as a usable expression, but .moduleY is not a valid expression.
5.8. Special considerations for __main__
The module is a special case relative to Python’s import system. As noted , the __main__ module is directly initialized at interpreter startup, much like and . However, unlike those two, it doesn’t strictly qualify as a built-in module. This is because the manner in which __main__ is initialized depends on the flags and other options with which the interpreter is invoked.
5.8.1. __main__.__spec__
Depending on how is initialized, __main__.__spec__ gets set appropriately or to None.
When Python is started with the option, __spec__ is set to the module spec of the corresponding module or package. __spec__ is also populated when the __main__ module is loaded as part of executing a directory, zipfile or other entry.
In __main__.__spec__ is set to None, as the code used to populate the does not correspond directly with an importable module:
Note that __main__.__spec__ is always None in the last case, even if the file could technically be imported directly as a module instead. Use the switch if valid module metadata is desired in .
Note also that even when __main__ corresponds with an importable module and __main__.__spec__ is set accordingly, they’re still considered distinct modules. This is due to the fact that blocks guarded by if __name__ == "__main__": checks only execute when the module is used to populate the __main__ namespace, and not during normal import.
{kind=link}
{kind=link}
{kind=link}
{kind=link}